Databricks
Connector Details
| Connector Attributes | Details |
|---|---|
| Name | Databricks |
| Description | The Databricks platform is a unified analytics solution designed to accelerate data-driven innovation by enabling seamless collaboration between data engineers, data scientists, and business analysts. It provides a powerful environment for processing, analyzing, and visualizing large-scale data with built-in support for machine learning and AI workloads. Leveraging Apache Spark at its core, Databricks simplifies the development of complex data pipelines, while ensuring scalability and performance. With integrated data lakes, real-time streaming, and collaborative notebooks, Databricks empowers organizations to extract actionable insights, optimize workflows, and drive transformative outcomes across various industries. |
| Connector Type | Class B |
Features
| Feature Name | Feature Details |
|---|---|
| Load Strategies | Full Load |
| Metadata Extraction | Supported |
| Data Acquisition | Supported |
| Data Publishing | Not Supported |
| Automated Schema Drift Handling | Not Supported |
Delta Sharing vs Data CopyDatabricks Unity Catalogs natively support delta sharing. Our Databricks connector does not use this technology, as it is already possible within the Databricks Workspace experience (see documentation here). If you want to use Delta Share instead of data copy, simply follow the steps in the Delta Share documentation above.
Our connector copies data from one catalog to another. Outside of having a manipulatable copy of the data rather than a Delta Share read only version, the Empower Databricks connector also allows you to take advantage of the Type 2 history stored in your bronze layer tables without having to only use Time Travel.
Source Connection Attributes
| Connection Parameters | Data Type | Example |
|---|---|---|
| Connection Name | String | DATABRICKS |
| Server hostname | String | Server Hostname |
| Token | String | <your-dayabricks-token-here: dapi**> |
| HTTP Path | String | HTTP Path |
| Catalog | String | Catalog name |
| Silver Schema (Optional) | String | |
| Bronze Schema (Optional) | String |

Connector Specific Configuration Details
-
Databricks connector has optional values such as Bronze Schema and Silver Schema
-
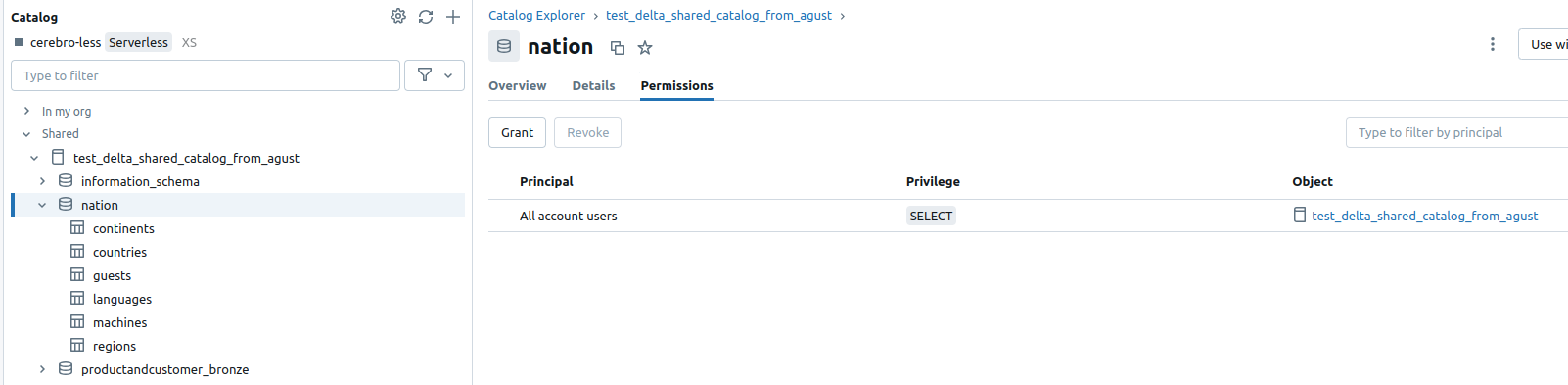
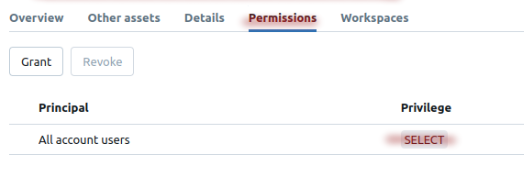
If you are using Delta Sharing, ensure that the
PROVIDERhas assigned the correct permissions on the source catalogs, tables, etc., that theRECIPIENTwill access. At a minimum, read access is required. You can verify this by running a simple select query. -
The cluster you will use with Databricks should be set up with
Unity Catalog. -
-
Set up the authorization. You can select one of the strategies: Personal access token authentication (PAT) or Authenticate access to [Azure] Databricks with a service principal using OAuth (OAuth M2M)
4.1 Personal access token authentication (PAT)
Generate the access Token for the user:
-
Log in to Databricks Go to your Databricks workspace URL and log in.
-
Open User Settings Once logged in, click on your user profile icon in the upper right corner of the screen. From the dropdown menu, click User Settings.
-
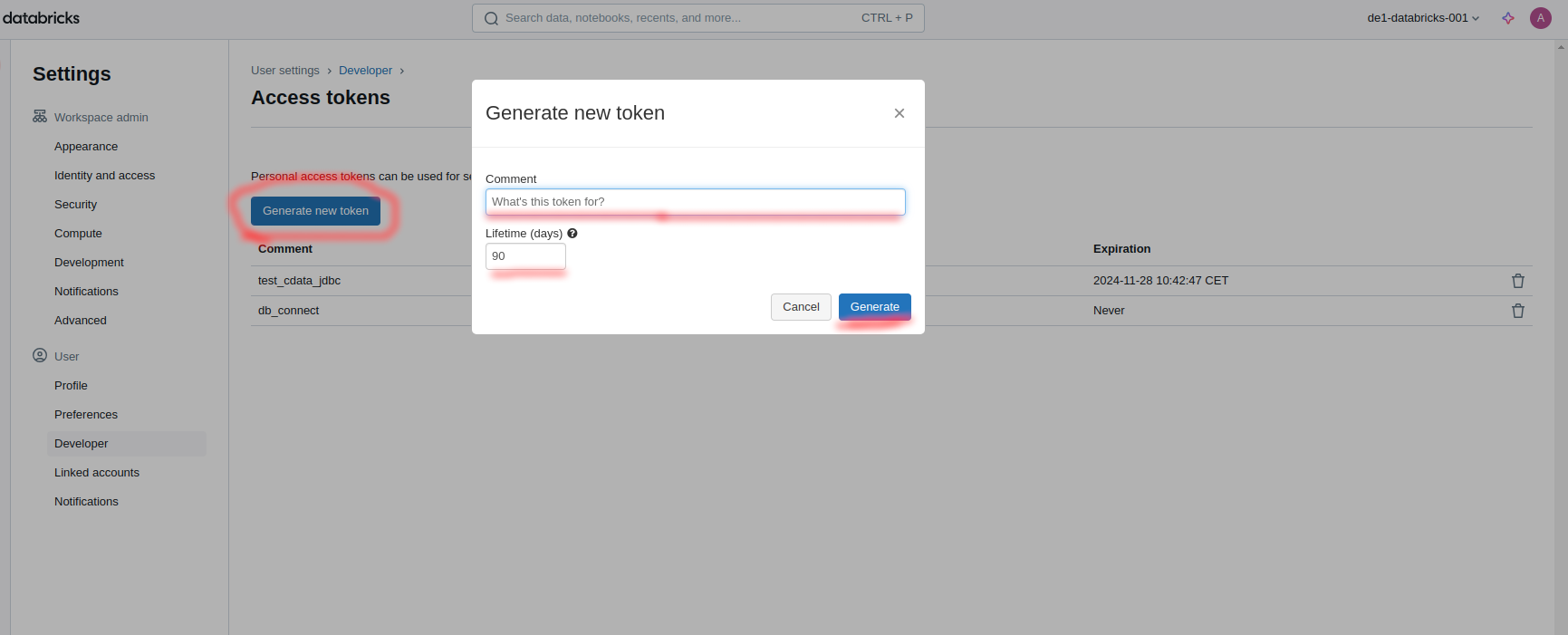
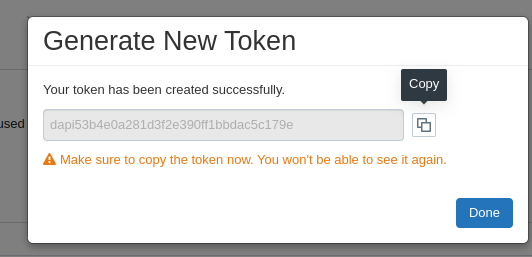
Generate a New Token Under the Access Tokens tab, click the Generate New Token button. In the dialog box, provide a comment or description for the token (optional but recommended). Optionally, set an expiration date for the token. If no expiration date is set, the token will last for the default period, which varies by workspace configuration. Click Generate.
-
Copy and Save the Token After generating the token, copy the token immediately as it will only be shown once. Store it securely (e.g., in a password manager or a secure environment).
-
Use the Token You can use the token in various APIs, SDKs, or CLI commands to authenticate with Databricks.
-
-
-
Official documentation:
-
Databricks personal access token authentication
4.2 Authenticate access to [Azure] Databricks with a service principal using OAuth (OAuth M2M)
client_id, secret
-
Log in to Databricks Go to your Databricks workspace URL and log in.
-
Open User Settings Once logged in, click on your user profile icon in the upper right corner of the screen. From the dropdown menu, click User Settings.
-
Application ID is a
client_id: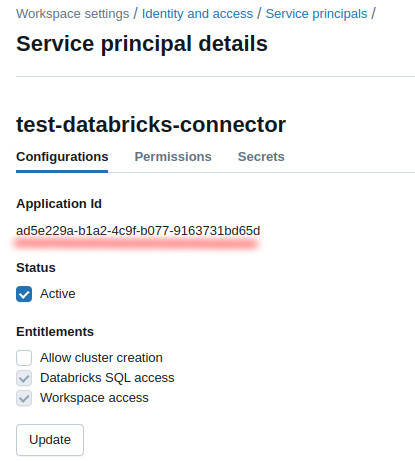
-
Select the tab
Secretsand pressGenerate secret: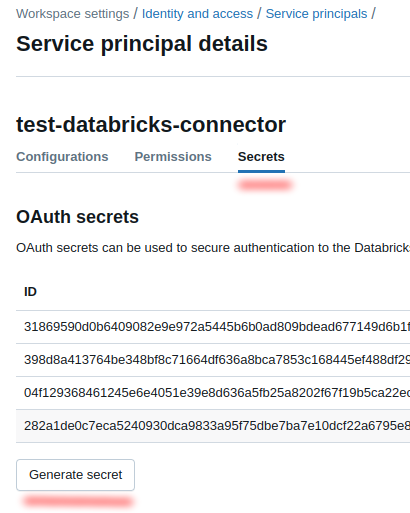
-
Save the
SecretandClient IDfor the connector: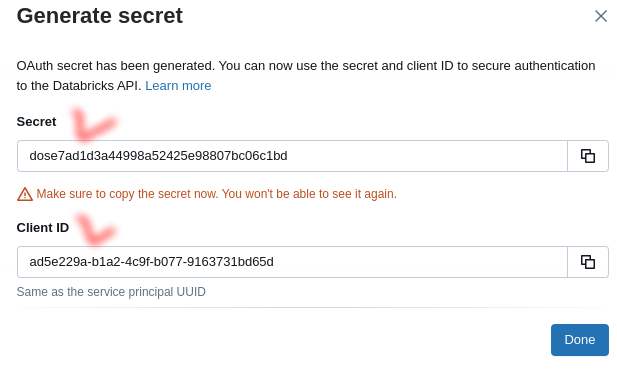
Official documentation:
- Azure Databricks personal access token authentication
- Authenticate access to Databricks with a service principal using OAuth (OAuth M2M)
-
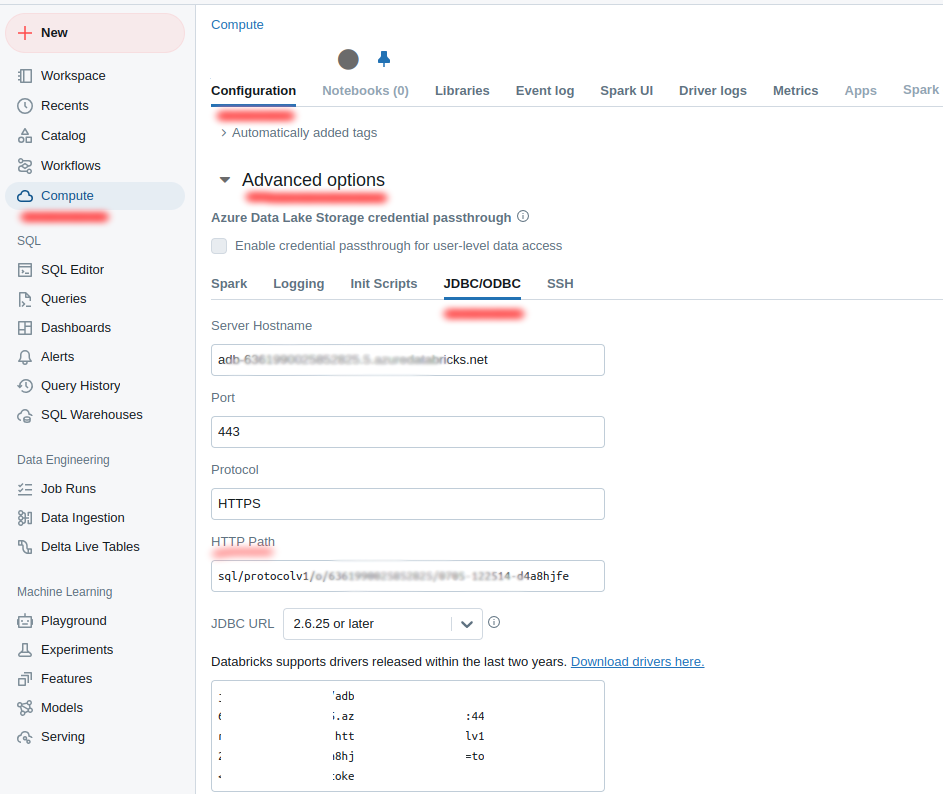
Open the list of available clusters or warehouses. Choose your own and get from the cluster settings the next values:
-
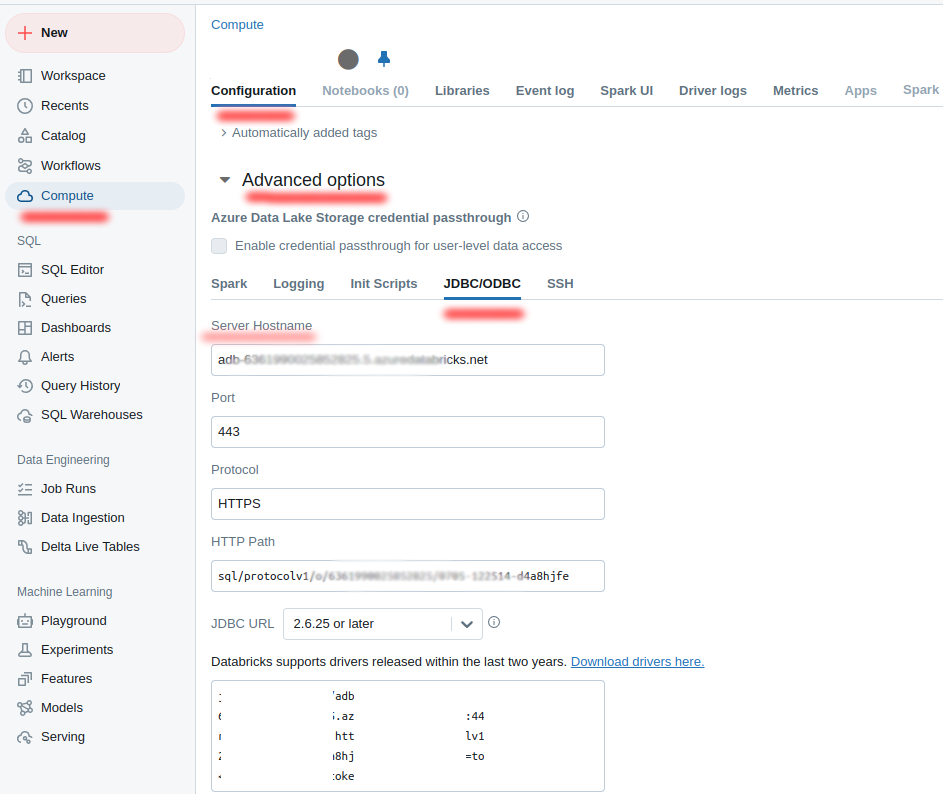
HTTP pathfromAdvanced options:-
Server hostnamefromAdvanced options:-
-
-
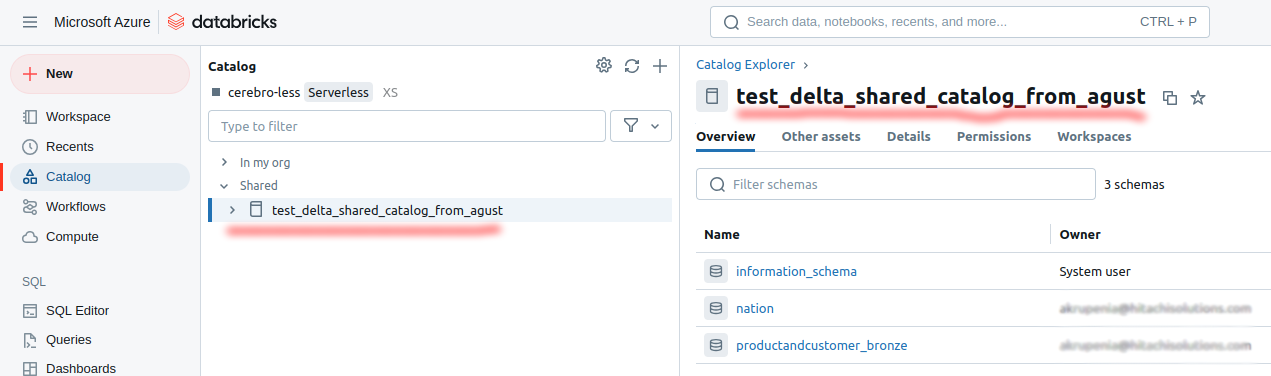
Get the
Catalog namefrom the catalog explorer, but make sure to check thepermissions. You need sufficient permissions to read both the catalog and the schema. -
Troubleshooting
PAT
- Pay attention to the access to specific catalogs to tables. Some of them or a whole catalog could demand access to the SELECT command:
-
- It is possible that using the extractor you can experience connection issues regarding the Grant Access to the catalog. This is common while extracting a sub-set of the ObjectName's fields. There may be an issue with the ObjectName which has a required or mandatory set of "key" columns to capture. The user may be missing the required sub-set of columns (see Custom Extraction Mandatory keys below).
- Common issues and solutions related to unit testing of the connector.
Service principal (OAuth)
-
Make sure your service principal has access to the catalog and sufficient privileges to work with it.
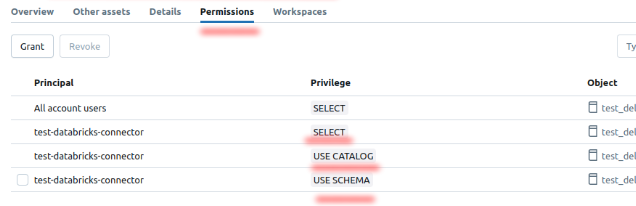
-
If you're using a warehouse, ensure that the service principal's permissions are also extended to that warehouse.
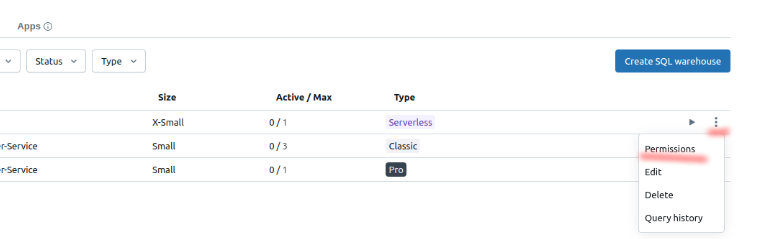
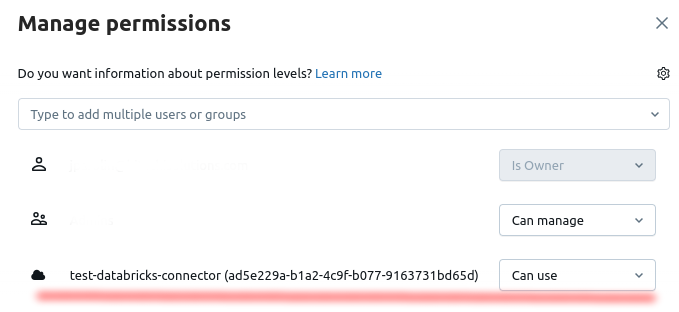
-
If you're using a cluster, ensure that the service principal's permissions are extended to that cluster, and the cluster type SHARED.
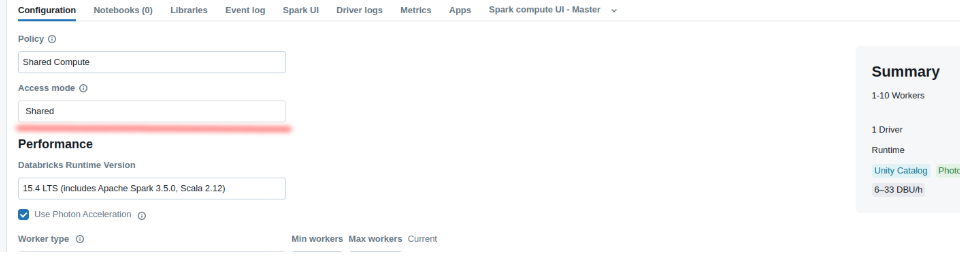
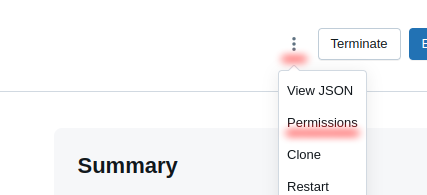
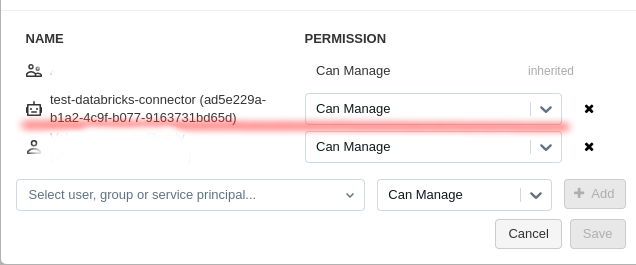
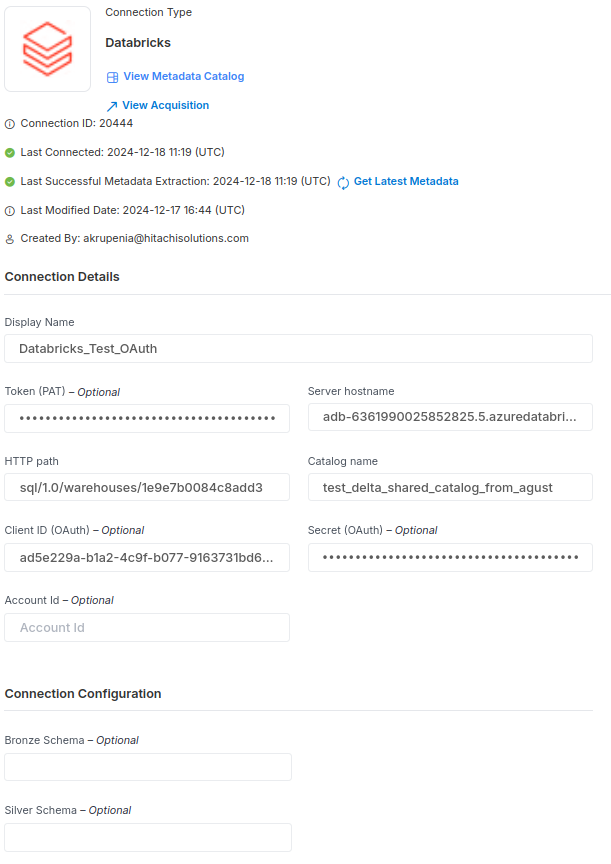
Screenshot To Use Connector
If you are going to use the PAT auth strategy then skip input the Client ID(OAuth), Secret (OAuth).
If you want to use OAuth then fill inClient ID(OAuth), Secret (OAuth)and skip Token (PAT).

Updated about 1 month ago