Batch Extraction
What is Batch Extraction?
Batch extraction is the process through which Empower uses one cluster to run object acquisition for all objects of a task, rather than one-cluster-per-object. By default, all connectors that can support Batch Extraction will use it. See Supported Source Types below for which source types can support Batch Extraction.
Configuration Settings
You may configure specific parameters for Batch Extraction to optimize the extract process for speed and costs if you have Advanced Options enabled.
Cluster Settings are Shared!Whatever cluster settings you set for Batch Extraction will be shared with ingestion for this same task. For example, configuring an Interactive Cluster for means that both extract and ingest will use this same cluster during Acquisition.
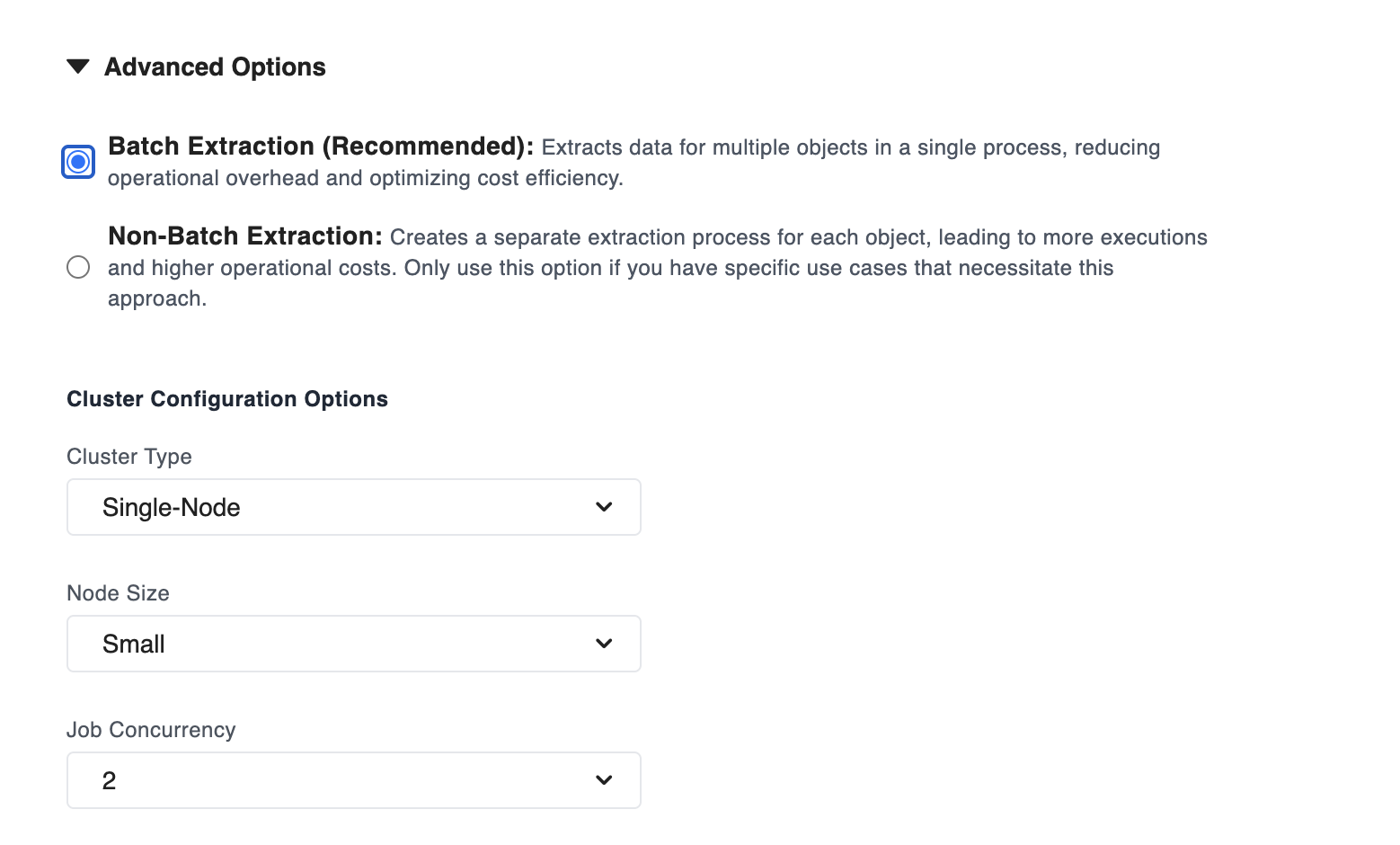
When Batch Extraction is selected, you may elect to customize certain cluster parameters for optimization purposes.
Batch Extraction (Recommended): This setting is optimal for executing data extraction efficiently. It processes multiple data objects together in a single, streamlined operation, conserving resources and minimizing execution time.
Non-Batch Extraction: This setting will process each object individually. Only choose this option if your specific use cases require it, but be aware that it can result in higher operational costs due to increased executions.
If Batch Extraction is selected, you may enable precise control to optimize performance based on your specific acquisition requirements.
Cluster Type
The cluster type determines the computing setup for processing your data. There are three options:
- Interactive: This type allows you to specify a specific cluster you want to be used by entering the name of the cluster.
- Single Node: Utilizes one processing unit, suitable for simpler tasks. This option will affect the available configurations for the other settings below.
- Multi-Node: Employs multiple processing units for handling larger or more complex data operations efficiently. Like Single Node, choosing this type will adjust options available in the subsequent settings.
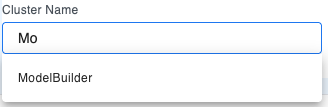
Interactive Cluster Selection
Empower will automatically suggest existing interactive clusters it can see in your environment.

Start typing to quickly filter this list.
Node Size
Node size adjusts to the computational power allocated for your tasks within the cluster. Selecting a node size—Small, Medium, or Large—affects the processing capacity and resource availability, allowing you to balance performance requirements against cost.
Spark Workers
Spark Workers are additional processing units that can be added atop the base worker within a Multi-Node setup. Increasing the number of Spark Workers enhances the distributed computing capabilities, allowing more effective distribution and parallel processing of data workloads.
Job Concurrency
Job Concurrency pertains to the number of jobs that can run simultaneously within the cluster. By configuring this option, you can enable parallel execution of multiple tasks, maximizing resource utilization and throughput, particularly beneficial for larger node sizes.
Supported Source Types
The following data sources are supported for batch extraction:
- Service Now
- Argus
- Kronos
- Azure Cost Management
- Azure Devops
- AttendanceOnDemand
- Microsoft Access
- Guild Quality
- Five9
- Azure Data Lake Storage
- Facebook Ads
- Workday
- Workday RaaS
- Google Analytics
- Textura
- Kafka
- Azure EventHubs
- Dynamics CE - Direct
- Dynamics FO - Direct
- Dynamics FO - Synapse Link
- Dynamics CE - Synapse Link
- Dataverse
- Databricks
- Birdeye
- SAP SAC
- ORIGAMI
- Primavera P6
- NetSuite
- Azure SQL Server
- Salesforce
- MySQL
- PostgreSQL
- CLMA
- Microsoft Entra
- Snowflake
- FTP Server
Updated 9 months ago