Staging Data Transformations
Follow this guide to create staging notebooks required for your model defined in the Model experience.
Acquiring Data to TransformThis guide assumes that you have already finished the Data Acquisition process. Follow Connect or Acquire for more details if necessary.
What are Staging Transformations?
Staging transformations are utilized to define transforms that produce staging data essential for modeling, sourced from the Silver Layer of the Medallion Architecture.
The Staging Layer is not the Gold Layer. Once staged, data in the staging layer will be incrementally merged into the target gold layer entity.
Example:
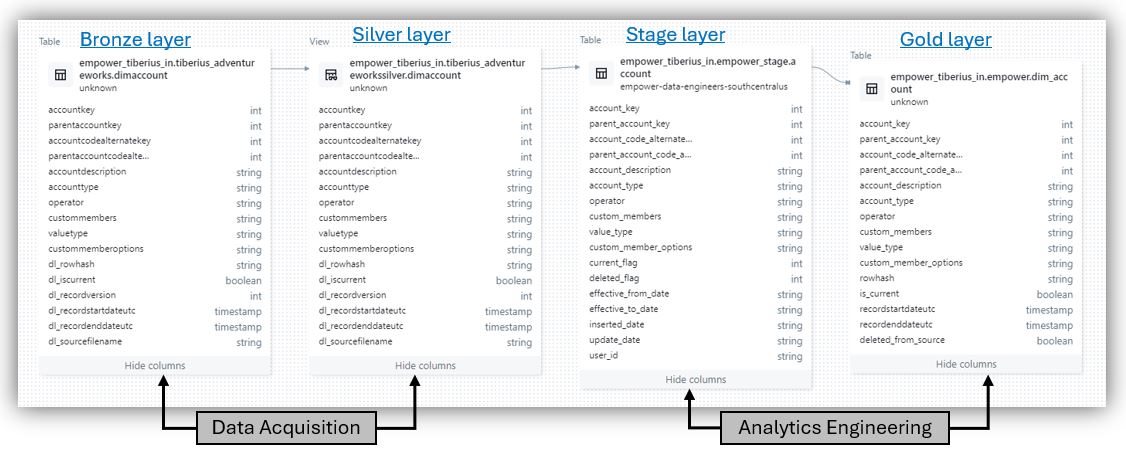
Example of Medallion Architecture for a dimension with stage layer.
In order to effectively prepare data for modeling or other purposes, dedicated notebooks are used to define any needed transformations that need to be applied to the data before merging into the data model entity in your Gold Layer.
Empower deploys a dedicated location in the Lakehouse to place these transformation definition files. It can be found in /Workspace/DmBuild/Dimensions and /Workspace/DmBuild/Facts for your model dimensions and facts respectively.
Tip: This location is just a suggestion. Any folder location in the Databricks Workspace can be used to store the transformation definition files. For example, it can be good practice to deploy via a git repository with Databricks Repos.
Once the files are created and tested, provide the full path to the "SOURCE NOTEBOOK" column for the given entity in advanced options.
Any of the following methods can be used to create a stage layer:
- Stage Notebooks
- SQL Query
- CREATE Queries
- No Stage
1. Stage Notebooks
When your transformations are more complex and requiring multiple queries, a Databricks notebook can be used for executing any python, SQL, or spark code. This notebook should leverage the Empower Spark API to write the stage data. The notebooks have the same substitution values above provided as notebook widgets instead.
Tip: See the
SourceQueryTemplatein your Empower deployment for a more concrete example of how a collection of stage notebooks for an entire model may be employed.
Example:
# Databricks notebook source
from empowerspark.core.storage.delta_lake_handler import DeltaLakeHandler
# COMMAND ----------
# DBTITLE 1,Get/Set parameters
dbutils.widgets.text("source_table", "")
dbutils.widgets.text("catalog_name", "")
dbutils.widgets.text("target_table", "")
catalog_name = dbutils.widgets.get("catalog_name")
spark.catalog.setCurrentCatalog(catalog_name)
source_table = dbutils.widgets.get("source_table")
db_name, table_name = source_table.split(".")
dlh = DeltaLakeHandler()
# COMMAND ----------
# DBTITLE 1,Source Query
query = f"""
SELECT
AccountKey as account_key
,ParentAccountKey as parent_account_key
,AccountCodeAlternateKey as account_code_alternate_key
,ParentAccountCodeAlternateKey as parent_account_code_alternate_key
,AccountDescription as account_description
,AccountType as account_type
,Operator as operator
,CustomMembers as custom_members
,ValueType as value_type
,CustomMemberOptions as custom_member_options
,'sysuser' as user_id
,dl_recordstartdateutc as modified_date
FROM {catalog_name}.db_silver.dimaccount
"""
try:
source_query = spark.sql(query)
dlh.write_delta_table(source_query, table_name, db_name, mode="overwrite")
except Exception as e:
dbutils.notebook.exit(str(e))Note: The notebook exit call is to record error messages from the stage notebook to the state log tables. This is optional, but if no message is returned and the notebook fails, a generic error message will be recorded.
2. SQL Query
The simplest technique to stage data is to use a SQL query which defines a transformation to data that will be merged into the model. The query should be written in a SQL query file (".sql" extension) in the workspace Model Builder is executing.
Several substitutions are available in the query:
{{ source_table }}- The source entity for merging into the model - uncommon for SQL Queries.{{ target_table }}- The name of the model entity that will be merged into.{{ catalog_name }}- The unity catalog name for execution. Useful for promotion to other environments.{{ watermark(my_column) }}- A DSL to select the maximum value of the given column from the target_table. If the target table or column does not exist, this will return '1900-01-01' (with quotes). The default value can, optionally, be overloaded like{{ watermark(id, 0) }}. Useful for incremental strategies.
Example:
SELECT
AccountKey as account_key
,ParentAccountKey as parent_account_key
,AccountCodeAlternateKey as account_code_alternate_key
,ParentAccountCodeAlternateKey as parent_account_code_alternate_key
,AccountDescription as account_description
,AccountType as account_type
,Operator as operator
,CustomMembers as custom_members
,ValueType as value_type
,CustomMemberOptions as custom_member_options
,'sysuser' as user_id
,dl_recordstartdateutc as modified_date
FROM {{ catalog_name }}.db_silver.dimaccountNote: While developing these queries, you can execute the SQL query directly in the ".sql" file in Databricks to confirm functionality. This won't work with any substitutions, but those are entirely optional. For example, the above query would work fine without the
catalogsubstitution, but can instead set the default catalog on the testing cluster. This is equivalent to the behavior when run inside Model Builder.
3. CREATE Queries
Model Builder also supports using a CREATE query to generate data for staging with SQL files. Both TABLE and VIEW are supported. VIEWs have little overhead compared to a SQL Query, but come with the benefit that the stage data can be queried outside of Model Builder. Using TABLEs will materialize the data into a Delta table. This can be expensive computationally (this also prevents much of Spark's internal optimizations), but can be useful for debugging and observability using Delta table history and time travel.
The same substitutions are available in the query as with SQL Queries shown above.
Note: The queries are refreshed with every execution of Model Builder. This means a VIEW will automatically handle new columns or data type changes as the query is updated. For TABLEs, Spark's automatic schema evolution is enabled by default. Many schema changes can be handled automatically, but there are some cases that may require manual intervention.
Example:
CREATE VIEW {{ source_table }} AS SELECT
AccountKey as account_key
,ParentAccountKey as parent_account_key
,AccountCodeAlternateKey as account_code_alternate_key
,ParentAccountCodeAlternateKey as parent_account_code_alternate_key
,AccountDescription as account_description
,AccountType as account_type
,Operator as operator
,CustomMembers as custom_members
,ValueType as value_type
,CustomMemberOptions as custom_member_options
,'sysuser' as user_id
,dl_recordstartdateutc as modified_date
FROM {{ catalog_name }}.db_silver.dimaccount4. No Stage
If no stage source is specified, Model Builder will use the provided source entity name directly. This is non-standard, but could be useful if a bronze or silver table is already in the expected format to be directly merged into the model. Another potential use case is if a table or view is being created externally to the modeling engine, or coming directly from a source environment already transformed.
Updated about 1 month ago