Orchestration (DatabaseToStep Commands)
What are Step Commands?
The Step Command system is Hitachi's 2nd generation metadata-driven process to allow customers to customize the data processing workflow within the context of a metadata-driven pipeline. It allows the pipeline to morph, based on the configuration.
Step Commands provide a bird's eye view of your data estate's pipeline configuration for data acquisition, analytics engineering, and publishing of data. With Step Commands, you can specify which data you want to acquire into your Lakehouse, how you want to transform it, and where you want to publish it.
How are they useful?Step commands enable you to configure powerful data movement.
For example you can move data from multiple SQL Servers to be pulled into the Lakehouse, unified into one data model, and published to a Power BI report, with the whole pipeline triggering every day at 4pm.
Step Commands provide flexibility in data processing as a lightweight {user.glossary:DAG} tool.
Advanced Options FeatureModifying step commands is only available from the Advanced Options tab. To learn more about Advanced Options, or how to enable it, please see our Advanced Options guide.
Accessing Step Commands
Currently, step commands are modifiable through the Advanced Options tab. To navigate here, look on the left side of your Empower UI for the grid pattern, and click to the Database to Step Command tab.
To learn more about Advanced Options, or how to enable it, please see our Advanced Options guide.
Creating New Step Commands
Click on "NEW RECORD" to bring up the record creation modal. Fill out all relevant fields and click "CREATE" to generate a new record.
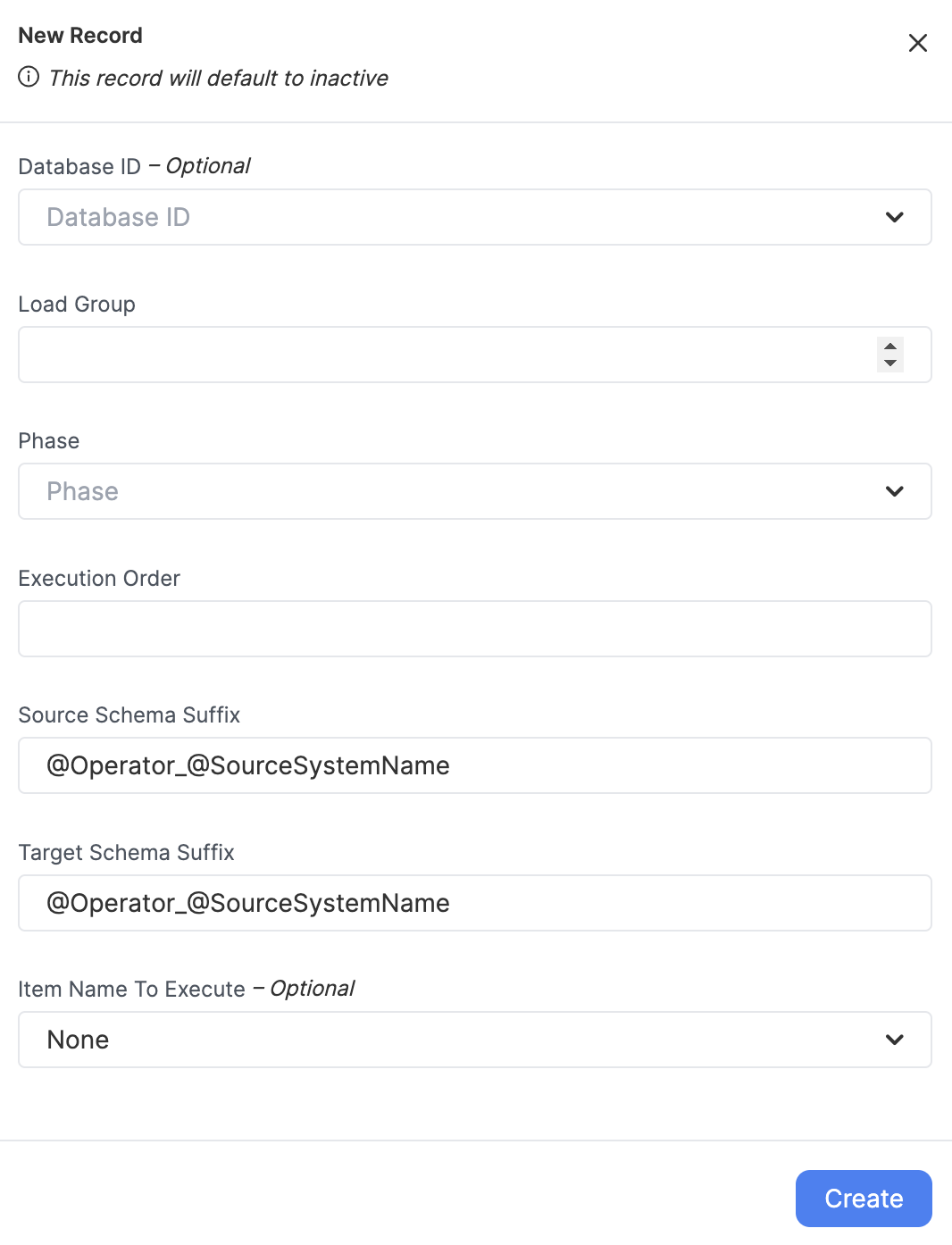
The most critical of theses fields are the Phase and the {user.glossary:Load Group}. Collectively, these two fields determine what occurs, and during which event group it will occur.
Phase
The Phase field determines what the action this Step Command will represent during a run of the {user.glossary:Load Group}. There are several to select from, and a Load Group can contain Step Commands with any or all of these phases.
| Phase Name | Description | Notes |
|---|---|---|
| Metadata | Triggers the extraction of metadata from the source system, like fields, object names, and schemas. | highly recommended before extract/ingest phases |
| Extract | Triggers the extraction of data from the source system. | |
| Delta | Triggers the ingestion of data from the extracted raw format into the data lakehouse bronze layer. | |
| Model Builder All | Triggers all models attached to this load group to be built. | Remember to activate your models, entities, and entity columns too |
| Publish | Triggers the data publishing phase to push data out of the platform into SFTP and SQL Servers. | |
| Power BI | Triggers a PowerBI dataset refresh. PowerBI will attempt to pull relevant tables for this load group into the associated dataset(s). |
Recommendation!We recommend having only one phase of each type per load group.
Load Group
The {user.glossary:Load Group} field associates this Step Command with other Step Commands, to be run in a sequence.
You may select any positive integer for a load group ID. Within a load group, the Phases will run in the following order always:
- Metadata
- Extract
- Delta
- Model Builder All
- Publish/PowerBI
Item Name to Execute
This column is specific to the Model Builder All and Power BI Phases. This will associate a model from Model Building to the Load Group.
Model Builder All
Item Name to Execute contains the name of the model that will be built during this phase. You may have multiple Model Builder All phases in a Load Group, one for each model to be built.
For example: empower-finance-division-a
Power BI
Item Name to Execute contains JSON defining the Workspace ID and Dataset ID for the Power BI environment and dataset respectively. The internal fields will be named as follows:
- workspaceId: defines the ID for the Power BI workspace.
- datasetId: defines the ID for the dataset within the Power BI workspace.
For example: {workspaceId: xyz-123-abc-xyz, datasetId: xyz-doh-ray-me-123}
Target Schema Suffix
This optional field is only used during the Delta phase. It enables you to define a custom schema for the bronze layer in your data lakehouse when data is ingested.
RecommendationWe highly recommend not changing this field if/after being defined.
We also highly recommend not defining this field unless you are absolutely sure you know what you are doing. Please discuss options with your delivery manager if you are unsure of Target Schema Suffix use.
Updated 9 months ago