Core Data Concepts
Understand the core data concepts that define how Empower ingests, processes, and governs your data.
Empower is built on a set of core data concepts that form the foundation for how it operates. Understanding these basics is essential for making sense of Empower’s approach to unified data management, scalable analytics, and robust governance.
Data Categories
Not all data is alike. Depending on its format and organization, it can be categorized:
- Structured Data: Data that adheres to a fixed schema or model. It's organized and easy to search, typically stored in relational databases or spreadsheets.
- Semi-Structured Data: Data that does not conform to the rigid structure of data models but it does contain tags or other markers to separate data elements and enforce hierarchies, e.g. XML and JSON files.
- Unstructured Data: Data that doesn't have a specific form or model. Often it can be text-heavy, like word documents or PDFs, but can also include images, videos, and social media posts.
ETL vs ELT
ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) are two approaches to moving data.
- ETL: Data is Extracted from a data origin, Transformed into a suitable format, and then Loaded into a data destination. This approach is best when the transformations are complex and when the quality and cleanliness of data are paramount.
- ELT: Data is Extracted from a data origin, Loaded into a data destination, and then Transformed. This approach is best when dealing with huge volumes of data, as it leverages the power of modern data warehouses to perform transformations.
Modern analytics no longer rely on brittle ETL pipelines that force data to be transformed mid‑flight to compensate for limited compute and storage.
Empower uses ELT to extract and load data into the Lakehouse first, then transform it at scale using cloud compute. This approach scales with big data and, critically, preserves an original, immutable copy of ingested data to support auditability, traceability, and compliance.
Warehouses, Data Lakes, and Lakehouses
"After extracting my data, where should I load my data?"
You have three choices:
-
Data Warehouse: Large repository used for storing structured data from multiple sources for analysis and reporting.
Uses a schema-on-write approach, meaning the schema is defined before writing into the warehouse.
-
Data Lake: Holds vast amounts of raw data in its native format until it is needed. It stores all types of data - structured, semistructured, and unstructured.
Uses a schema-on-read approach, meaning the schema is only defined when reading data.
-
Data Lakehouse: A strikingly new paradigm that combines the best elements of data lakes and data warehouses. It supports all types of data and offers the performance of a data warehouse with the flexibility of a data lake.
The Lakehouse can stored all three types of data: structured, unstructured, and semi-structured while still providing the powerful scaling ability of a warehouse. At its core, Empower uses the Lakehouse to centralize your data before any transformation occurs.
Medallion Architecture
Empower abides by the data management paradigm known as the Medallion Architecture. Medallion focuses on enabling rapid, reliable, and scalable data pipelines, while providing robust data governance and quality checks.
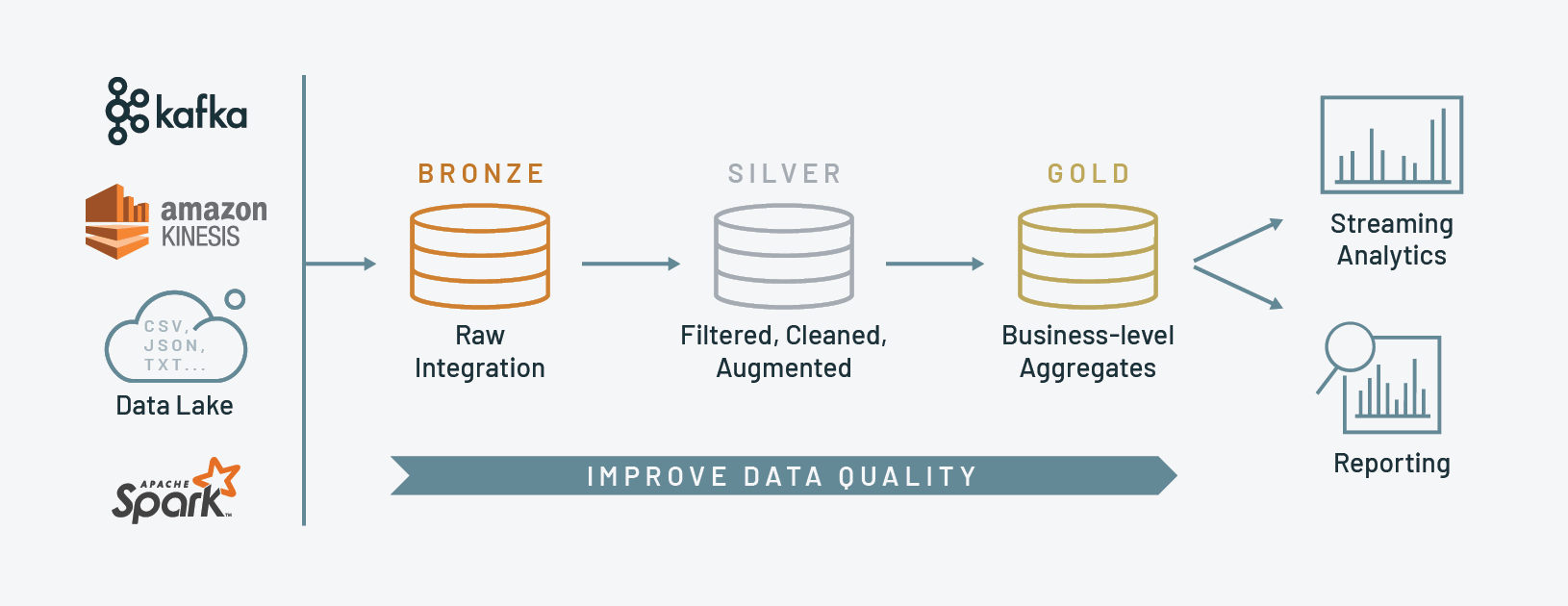
Data quality improves as it moves from left (Bronze) to right (Gold)
The Medallion Architecture is typically represented as a series of stages, each with a specific role in data processing. Here's a simplified representation:
- Bronze Layer: The "raw" or "ingest" layer.
Where data is ingested from various sources in its original, unprocessed form. The goal is to capture a complete and accurate representation of the source data. - Silver Layer: The "clean" or "trusted" layer.
Where data is processed, cleaned, and transformed. Quality checks and data governance rules are applied in this layer to ensure the data is accurate, reliable, and ready for analysis. - Gold Layer: The "semantic" or "consumption" layer.
Where data is further transformed and enriched into a format suitable for consumption by end-users (like business analysts) or applications (like BI tools). The goal is to create a user-friendly, high-value dataset that drives insights and decision-making.
Updated 25 days ago