Metadata Catalogs
View metadata about a specific Data Source
Overview
Metadata is "data about data". In Empower, metadata contains information about the schemas, tables, objects, and fields contained within the data source. Empower extracts metadata while automatically detecting and auto-resolving Schema Drift.
Empower extracts metadata from your data sources so that you can decide what data to ingest into your deployment using the Metadata Catalog.
What is a Metadata Catalog?A metadata catalog is a view of all the tables/objects and their schemas from a Data Source. For each table/object, you can also view all fields within it, as well as an estimated number of rows within this table/object. You can define what data and how that data is brought in using the catalog.
You can view the metadata catalog of any data source with at least one successful metadata extraction in its lifetime. To do so, select a data source and click "View Metadata Catalog".
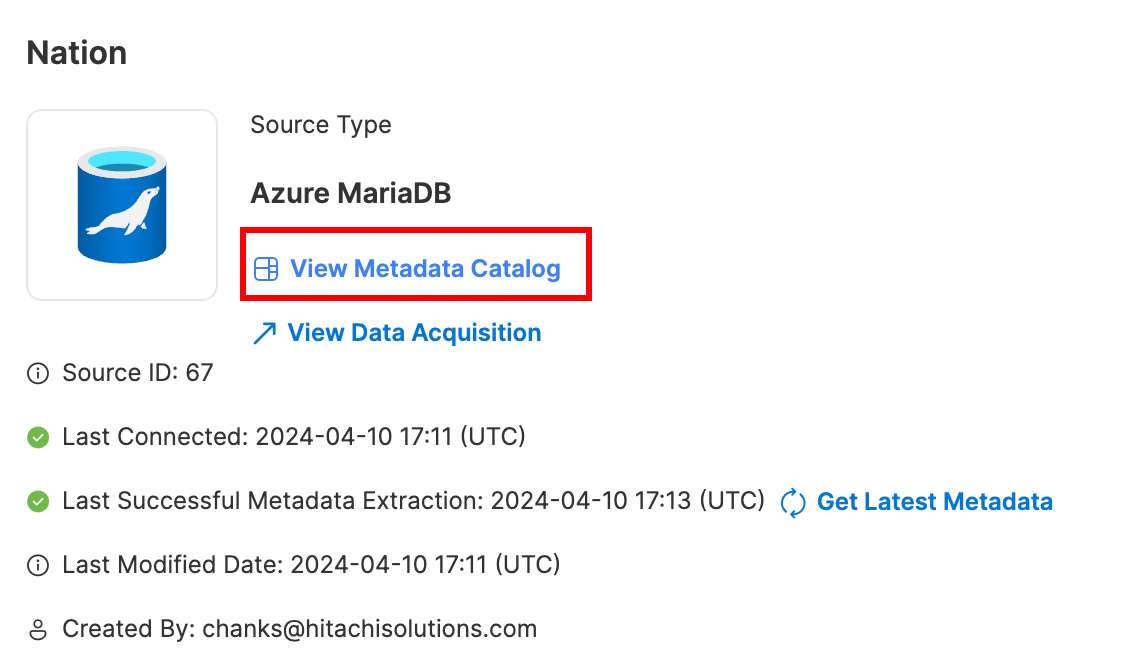
You can "View Metadata Catalog" on any source that has at least one successful metadata extraction in its lifetime.
The Metadata Catalog provides a view of all metadata that has been extracted from this source using the provided credentials. With Write access, you can configure different load strategies, watermarks, field-level enablement, and even global object-level enablement.
Automatic Saving!Every change you make to the metadata catalog is automatically saved.
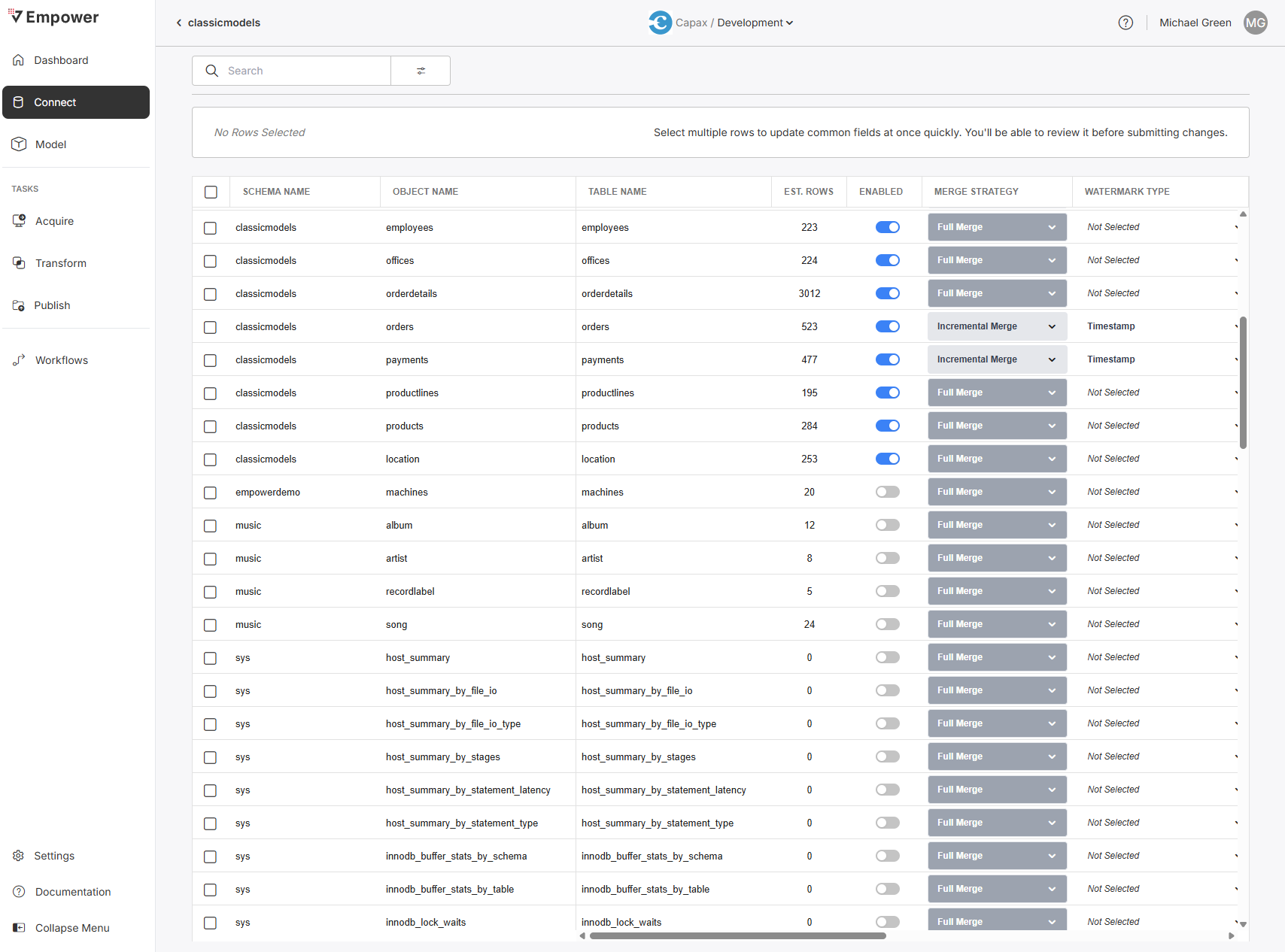
Empower enables you to configure how data is brought into your Lakehouse, but it does not manipulate data on the source itself!
Enabled
Fields
From the metadata catalog View Field Details column, you may configure Empower to bring in certain object fields while ignoring others.
Click "View Field Details" to bring up the Field Details modal and select which fields you wish to enable/disable. When disabled, this field will no longer be extracted during Data Acquisition.
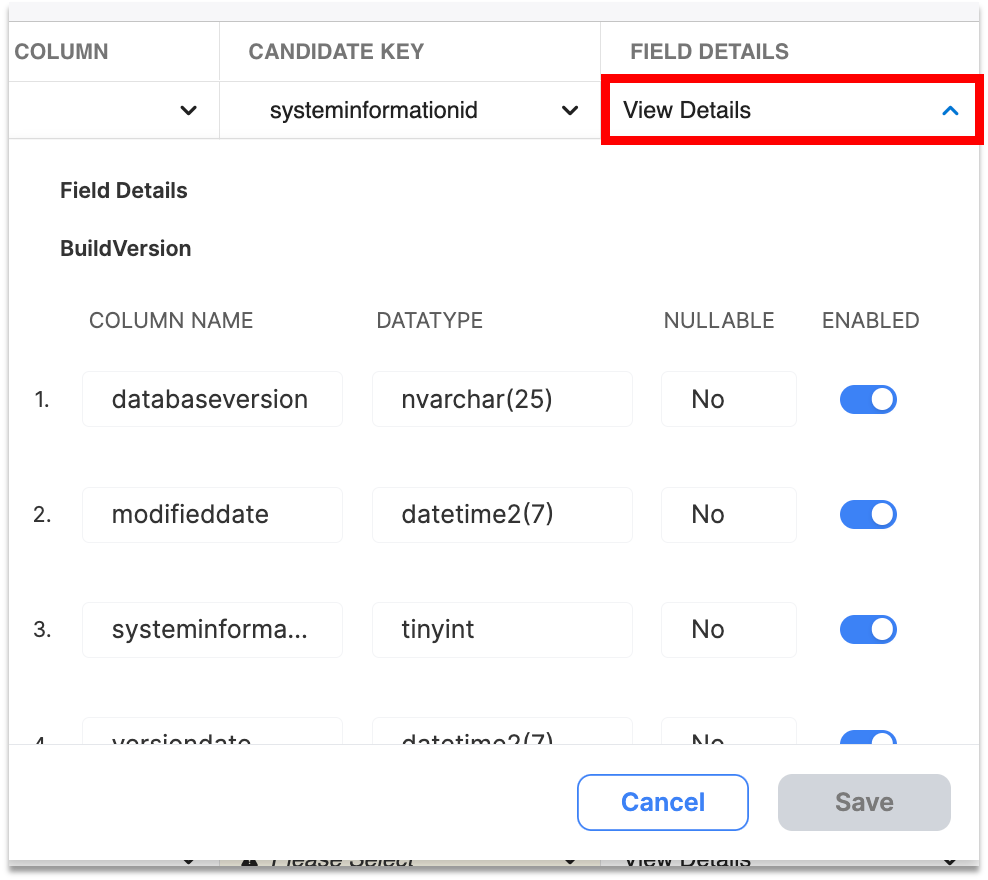
Enable or disable fields for Data Acquisition.
Objects
Entire objects can also be globally enabled/disabled from the metadata catalog. Enabling or disabling an object is as easy as flipping a toggle in the "Enabled" column.
As with fields, disabling an object means it will no longer be extracted during Data Acquisition. Additionally, no new Data Acquisition Flows will be able to include this object in their flow until the object is re-enabled.
Bulk Enablement
You can use the select boxes to the left side of the Metadata Catalog to bulk enable/disable objects.
When you select multiple objects, the bulk edit feature will allow you to modify column values for multiple entries at once.
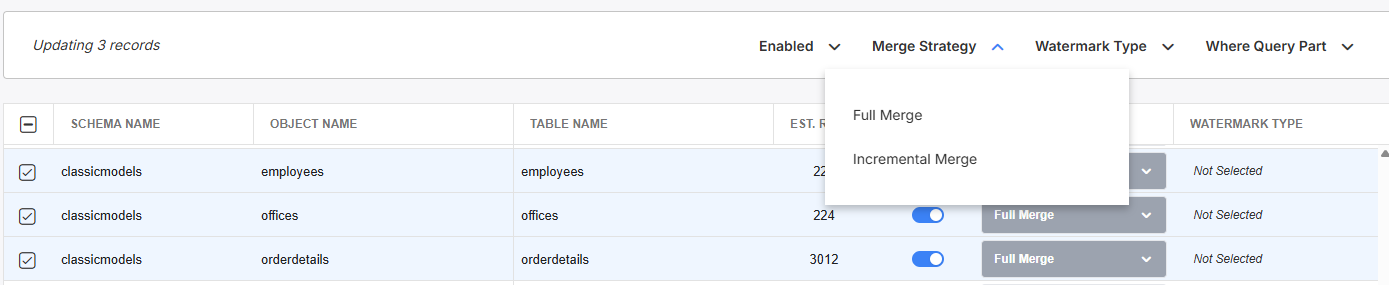
Select which objects you wish to bulk enable/disable and make changes at the top of the screen.

At the bottom of the screen, you may discard any changes made or review your bulk edit changes.
Clicking on review will take you to a change review screen, which filters for just the entries you will be modifying with this bulk edit modification. You will see the final values of each entry in this table.
- Click 'Save' to cement these changes.
- Click 'Back' to go back to the previous screen, where you can make further modifications.
- Click 'Discard All Changes' to undo any bulk change and be taken back to the metadata catalog page.
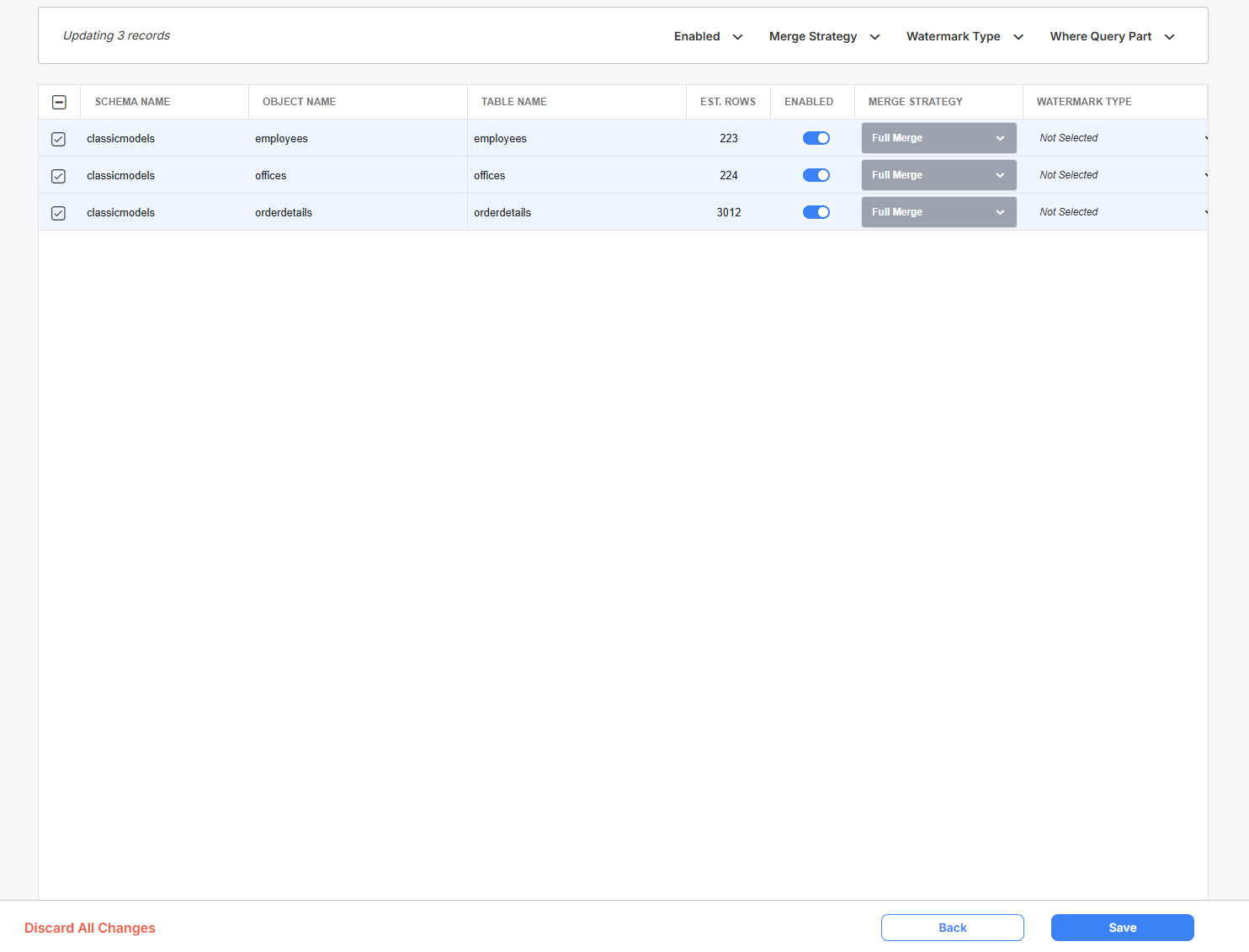
'Save' will realize your bulk edit changes on the selected rows.
Merge and Load Strategies
Merge Strategies
You can select which objects you want Tasks to be able to acquire from using the "Enabled" column. Empower provides several merge strategies to manage data ingestion from various sources into target tables. Each strategy is designed to handle specific data management scenarios effectively.
- FULL MERGE: This strategy fully refreshes the target table by reading the entire source dataset. It updates the target table with the new data, deletes records that are not present in the source, and appends new records from the source. Most suitable for datasets without watermark columns for incremental updates.
- INCREMENTAL MERGE: This strategy only loads new or changed data into the target table using the watermark column. It fetches new records relative to the last extraction, merges them with the target table, updates existing records, and drops older versions based on the watermark. Suitable for regular incremental updates.
If you have Advanced Options enabled, there are a few additional options to choose from:
- FULL DEDUPE MERGE: This strategy also performs a complete refresh of the target table but includes a deduplication step. It reads the entire source dataset and uses the watermark column to keep the latest version of each record while dropping older duplicates. It deletes records in the target not present in the source and appends new records from the source. Ideal for tables needing deduplication without incremental updates.
- DIRECT MERGE: Similar to Incremental Merge, but this strategy does not use the watermark column during ingestion. It assumes all incoming records are newer and merges them into the target table without deduplication. Ideal when data is always unique and deduplication is not needed.
- APPEND MERGE: This strategy appends new rows to the target table by checking rowhash values. If a source rowhash is not present in the target, it adds the new row. This is useful for log tables or when you need to append new records without modifying existing data.
- CHANGE TRACKING: Available only for SQL Server and Azure SQL Database connections. This strategy uses change tracking to ingest only modified records since the last load. It ensures efficient incremental updates by focusing solely on the changed data, minimizing data load and processing time.
- APPEND MERGE DEDUP This strategy appends only the newest version of each candidate key(s) from the incoming dataset, based on the watermark column. Any duplicates in the incoming data are dropped by identifying the latest record per candidate key using the watermark. Unlike other merge strategies, this approach does not update or delete existing records in the target. It simply appends new, deduplicated records. This is useful when the data contains duplicates but no merge is required—only additions of the most recent versions.
- DIRECT MERGE DEDUP This strategy is similar to Direct Merge, but it includes a de-duplication step during ingestion. The watermark column is used to identify and retain only the latest record per candidate key(s) in the incoming data. No row-level comparison (rowhash) is done—any newer, deduplicated record is assumed to be correct and is either inserted or replaces the matching record in the target. This strategy is suitable when incremental data is guaranteed to be up-to-date but may include duplicates that need to be filtered out.
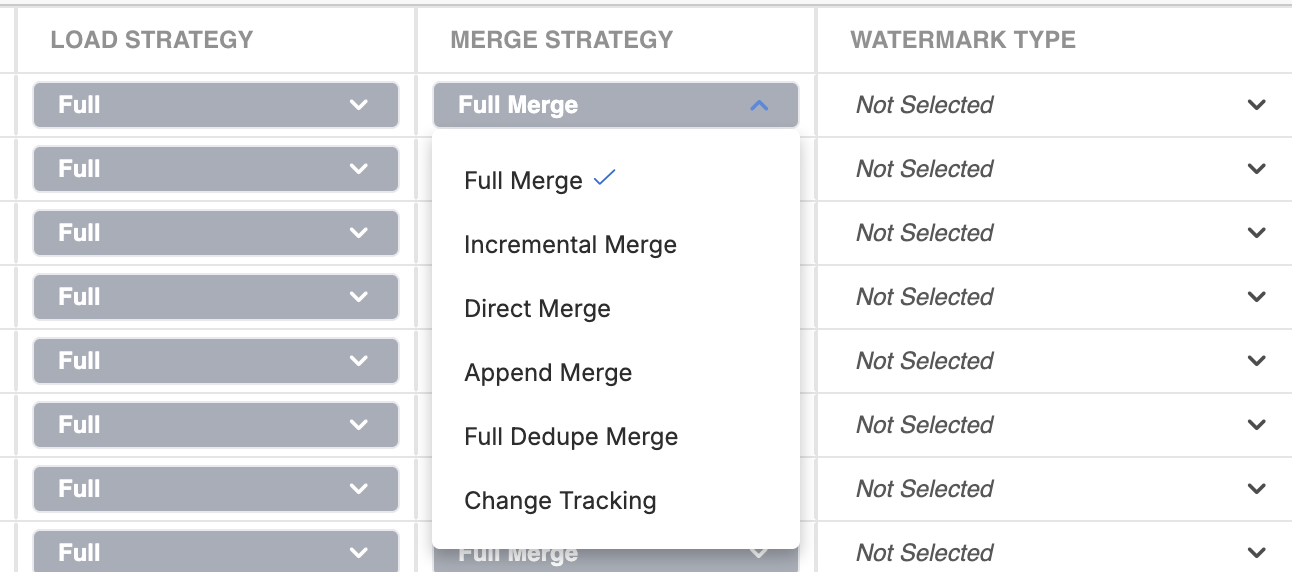
Load Strategies
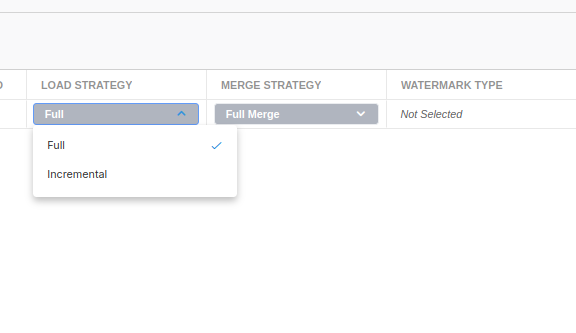
By default, your load strategy will automatically be selected for you based on the chosen merge strategy, see below for mapping details. However, you can override the load strategy option as well with one of the following selections. Unless you have a very specific use case, we strongly recommend leaving the automatically selected load strategy value.
- Full Load: This is the default load strategy. This strategy does a complete refresh of the target table. The entire source data set is read from the source and used to update the target table. Any records in the target that are not in the source are deleted. Any records in the source that are not matched get appended. This strategy is most useful for tables that have no watermark columns to use for an incremental extraction.
- Incremental Load: Loads an incremental dataset to the target table. A watermark column is used during extraction to only fetch records that are new relative to the last extraction. This method does not capture deletions from the data source!
Merge Strategy to Load Strategy Automated Selection Mapping
As noted above, your load strategy will automatically be selected for you based on the chosen merge strategy. These can be overridden if needed after selection.
| Merge Strategy Selected | Load Strategy Auto Selected |
|---|---|
| Full Merge | Full |
| Incremental Merge | Incremental |
| Direct Merge | Incremental |
| Append Merge | Incremental |
| Full Dedupe Merge | Full |
| Change Tracking | Incremental |
| Direct Dedupe Merge | Incremental |
| Append Dedupe Merge | Incremental |
Watermarks
A critical part of incremental extraction, watermarks are used as a marker for the last successful data extraction. With these markers indicating the last record that was successfully processed, Empower can identify and scope the next extraction to only process new or updated data. Watermarks are can significantly reduce the volume of data movement and processing, leading to improved performance and lower resource usage.
You can select a column within an object to act as the watermark column. Empower's UI supports the following watermark methods:
- Timestamp: a datetime value column, e.g. modifiedDate.
- Integer: an integer data type value column, such as a unique ID value.
Candidate Keys
A candidate key is an attribute or a set of attributes that uniquely identify a record within a database table. Every table is defined by its ability to hold unique data entries, and candidate keys are critical for establishing this uniqueness. When Empower extracts metadata from data sources, it can use candidate keys to ensure that each record is unique and to manage updates or merges effectively.
You can select multiple columns (which will be concatenated together) from which to form a candidate key for an object. Though this field is not required, we highly recommend using it to decrease ambiguity in your data estate.
WhereQueryPart
You can also define a query you want the Empower system to perform to scope data acquisition before it enters the Lakehouse. Similar to the Where column of Publish Entities, it's as easy as writing a SQL WHERE clause. WhereQueryPart is a completely optional field. When this field is blank, Empower will bring in all data as defined by the Load Strategy.
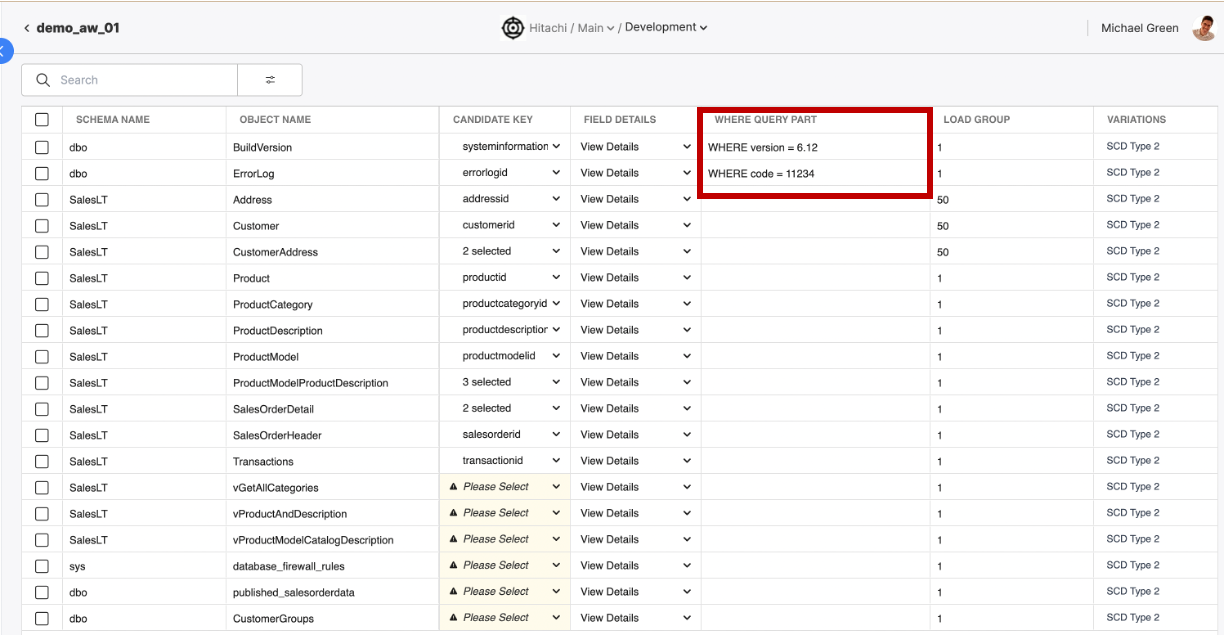
Write a SQL WHERE clause to restrict acquisition to a specified subset of data.
Under the hood, Empower will scope source data (defined by the Load Strategy) during Acquisition to only bring the rows that match the query into the Lakehouse.
Options
Clicking "View Options" will bring up the Options modal, a key-value dictionary used to specify special object-options for acquisition purposes.
The key-value options modal.
Only some data source types support object options. Today this short list includes:
To see what key-value pairs are supported today, visit the relevant connector pages.
Load Group (Advanced Users)
You can use the Load Group column to assign this object a Load Group for Step Command acquisition. This column will only be visible for users with Advanced Options enabled. Learn how to enable Advanced Options on the Advanced Options page.
Read about Load Group groups and Step Commands on the Orchestration page in Advanced Options.
Variations (Advanced Users)
This column will not have an affect on objects as it is only privately-preview-able for a handful of select users. Please contact the Empower product team for more information on this feature.
Updated about 1 month ago
What’s Next
You can learn how to trigger and schedule Data Acquisition next using Database to Step Commands. You can also learn how to Monitor Acquisition