Current Empower Resources
Resources
This document covers a technical description of the Empower resources which will be deployed to the customer's tenant.
Subscription and Resource Group layout
We highly recommend separating Empower's production environment at both a subscription and resource group level. Our recommendation is two subscriptions, one non-production and one production.
We also recommend having at least three environments. A development and staging environment which would be placed in the non-production subscription and a production environment in the production subscription.
Architecture Diagram
Note: While this diagram only shows one non-prod resource group, we highly recommend at least two non-prod resource groups. Multiple have been omitted to help keep the diagram clean but all non-prod resource groups are identical.

Service Principals and Access
Please see the Empower Access Details documentation for specific details regarding what child service principals will be created in your environment.
Empower Environment
Description: Empower will deploy these resources to each environment resource group which form the core of the Empower product.
| Resource | Description |
|---|---|
| Databricks Access Connector | Provides databricks with a storage credential that is used to setup an external location in our storage account for the databricks catalog. |
| Databricks Workspace | Contains compute, workflows and notebook code required for Empower. |
| Datafactory - Client | This datafactory can be used for custom datafactory code and will not be overwritten by our deployments. |
| Datafactory - Empower | Contains Empower product pipelines and parameters. These get deployed every release and any custom changes made to this datafactory will be overwritten upon release. This datafactory contains a linked IR that points to the production IR host datafactory. See the production specific section below. |
| Event Grid Topic | Notifies databricks when a storage blob has been created by datafactory. |
| Keyvault | Holds all the secrets required by a specific Empower environment to function. This keyvault is currently managed through the use of access policies which must be applied to the keyvault in order to access secrets. |
| Log Analytics Workspace | Holds metric logs for the storage account deployed in your environment. |
| Network Security Group | This network security group is specifically for the databricks vnet. Contains the rules specifically outlined by databricks in their documentation. |
| Storage Account | Holds any data extracted by Empower in a datalake. The data will not leave your tenant. This storage account is accessible through a firewall. Databricks will access the storage account over private connection. |
| Virtual Network | Contains at least two subnets that each have 256 addresses. These subnets are the public and private subnets for databricks compute. 512 addresses are available for future features and additional subnets. |
Production Environment
Description: Empower will deploy these additional resources to your production environment.
| Resources | Description |
|---|---|
| Datafactory - Integration runtime | This data factories job is to hold the integration runtime for Empower. Each Empower datafactory and each client datafactory then links to the integration runtime datafactory. Only one IR datafactory exists by default per organization. |
Unity Catalog
Description: One Unity Catalog Resource Group is set up for each Azure region to which Empower has been deployed. This group contains resources listed in the table below. If your environment already contains a metastore in this region, only the networking components of this resource group will be set up.
| Resources | Description |
|---|---|
| Databricks Access Connector | This is used to setup the storage credential for the above storage account. |
| Private DNS Zones | This resource group contains two private dns zones. One for blob and the other for dfs A records for the various Empower private endpoints deployed in this resource group. |
| Private Endpoints | Each Empower storage account has a dfs and blob private endpoint within this resource group. These allow resources in the Empower resource groups to communicate with the storage accounts privately. |
| Storage Account | This storage account holds a container associated with the metastore. It can hold managed tables. Empower currently uses external tables so this container is not used by default. |
| Vnet | This vnet contains one subnet which holds the various private endpoints setup by Empower. Currently this subnet holds the private endpoints for Empower storage account. This vnet is peered to each databricks injected vnet. |
Logging resource group
Description: One logging resource group will be setup for each Empower organization. This resource group is managed by Hitachi to provide security alerts for Empower.
| Resources | Description |
|---|---|
| API connections | The API connections are sub-resources of the logic apps and provide connections from the Logic Apps to the Sentinel and Defender for Cloud services. |
| Log analytics workspaces | The Workspaces collects the resource activity logs from across the Empower deployment, and with the Sentinel service enabled on it, generates security alerts. |
| Logic Apps | The Logic Apps hook the Sentinel alerts and Defender for Cloud alerts into our ticketing system for review by the team. |
| Storage Account | This storage account is used to store read logs for the other Empower storage accounts. A storage account is used rather than a log analytics workspace due to storage accounts being much cheaper than a log analytics workspace. |
Databricks Workspace
Description: The following resources are set up at the databricks workspace level.
| Resources | Description |
|---|---|
| Catalog | Empower sets up one catalog per environment. These catalogs, unless desired by the customer, are not isolated. The catalog are associated with the corresponding external location defined above. |
| Compute | All compute used by Empower is job specific compute. It is created and spun up upon job run. Empower deploys two pre-defined clusters named DataEngineering-Interactive and ModelBuilder. These compute resources are deprecated and are awaiting safe removal from Empower. |
| External Location | Each environment specific storage account setup by Empower has a corresponding external location setup by the deployment process. This external location uses the corresponding external location. |
| Notebooks | Empower deploys many notebooks to the workspace. See the Databricks Code section of this article for more information about these notebooks. |
| Pools | Standard compute makes use of T-shirt sized pools deployed as part of Empower with the following names: XS-Standard-Pool, S-Standard-Pool, M-Standard-Pool, L-Standard-Pool, XL-Standard-Pool. These pools currently use DSv3 compute for clusters and have a pre-loaded spark version of 14.3 LTS. Any job clusters that are spun up make use of these pools. Empower also deploys three other pools: DataEngineeringDriverPool, DataEngineeringWorkerPool, and ModelBuilderPool. These are deprecated and are awaiting safe removal from Empower. |
| SQL Warehouses | Empower deploys one SQL Warehouse named PowerBI-Interactive. It is a small sized classic SQL warehouse. Databricks will soon be rolling out features to allow us to change this warehouse over to a serverless warehouse. Once this is rolled out generally to all customers, this warehouse will be shifted over to serverless. See documentation |
| Storage Credential | Each storage account deployed as part of Empower has a corresponding access connector deployed with it. This access connector is used to setup storage credentials for each storage account. |
| Workflows | Empower deploys four workflows: IaC - GrantDatabasePermissions, IaC - OneTimeMountSetup, OptimizeDelta, Vacuum Delta Tables. Additional workflows may be created by the customer or Data Engineer/Architect. |
Databricks Code
Description: This section covers the organizational structure of the Empower Databricks code.
Notebook Folder Structure
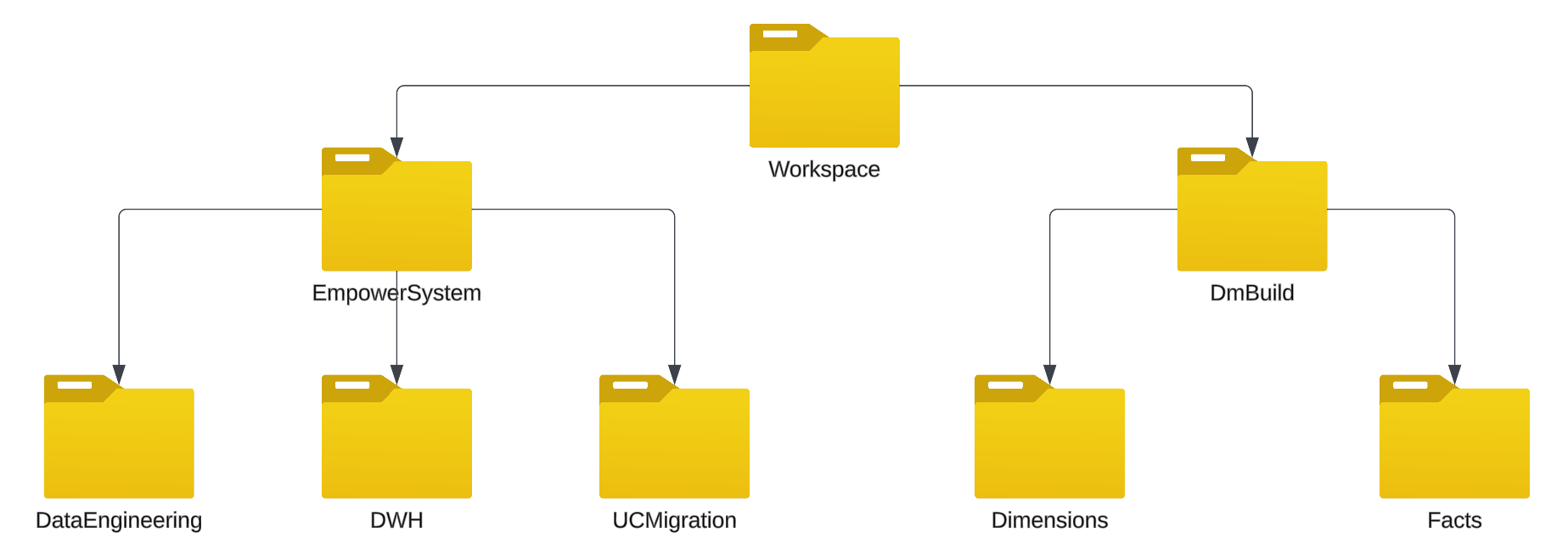
| Folder | Description |
|---|---|
| DataEngineering | The main organizational folder for Empower product code. |
| Dimensions | Source queries that are creating dimension tables for a data warehouse practice. These provide structured labeling information. |
| DmBuild | The main organization folder for client specific code. |
| DWH | Currently outdated assets awaiting removal. |
| EmpowerSystem | Empower product code and is maintained by the Empower product team. Custom notebooks must be placed outside this folder. Please talk with your Data Engineer/Architect for a good place to put them. |
| Facts | Source queries that are creating fact tables for a data warehouse practice. These provide measurements, metrics or facts about a business process. |
| UCMigration | One time run notebook useful for implementing Unity Catalog. |
Databricks Account
Description: The following resources are set up at the databricks account level. At least one databricks workspace must have been deployed in an Azure tenant to have an associated account. If your tenant already has a metastore in this region, then empower will integrate with the existing metastore.
| Resources | Description |
|---|---|
| Group | Empower sets up a data engineers group per azure region that holds various Empower resources and engineers. If it is desired, customers can make and manage their own groups and then add their group to the data engineers group, thus inheriting the group's permissions. See access documentation |
| Metastore | One unity catalog metastore is deployed per Azure region. The metastore is the highest level of databricks organization and contains the empower catalogs. |
| Network Connectivity Configuration | This feature is currently in public preview and is not part of the default Empower setup. If you would like more information on this feature, please see this documentation |
Secrets
Description: The following secrets are stored in each Empower keyvault as part of the automated deployment process. Additional customer specific secrets will be created by the Data Engineer/Architect.
| Name | Value |
|---|---|
| ad-tenant-id | Tenant ID of the environment |
| adb-access-token-id | A databricks PAT associated with the deployment service principal. |
| adb-app-reg-id | App ID of the databricks service principal |
| adb-app-reg-secret | Secret of the databricks service principal |
| adb-cluster-{cluster name}-id | The id of all of the static clusters created by the Empower deployment. |
| adb-oauth-client-id | Empowerclient id |
| adb-oauth-client-secret-name | Empower client secret name |
| adb-oauth-token-endpoint | Empower token endpoint |
| adb-resource-id | Resource ID of the databricks workspace |
| adb-workspace-url | The url of the databricks workspace |
| empower-api-url | Base URL of the Empower API |
| keycloak-client-secret-{enterprise}-{environment}-df | Empowerclient secret |
| pbi-app-reg-id | App ID of the Power BI service principal. |
| pbi-app-reg-secret | Secret of the Power BI service principal. |
| pbi-tenant-id | Tenant ID of the Power BI workspace |
| org-pbi-app-reg-id | App ID of the org level Power BI service principal. |
| org-pbi-app-reg-secret | Secret of the org level Power BI service principal. |
Integration Runtime
Description: Empower currently requires the deployment of a single integration runtime. The compute for this IR can be deployed in either Azure or Non-Azure environments. These IR nodes will need access to all desired data sources that cannot be pulled through the Auto-Resolved Integration Runtime.
After the deployment of Microsoft fabric, we will be able to explore the option of supporting multiple integration runtimes. At present, multiple organizations will be needed if multiple integration runtimes are desired.
If the integration runtime nodes are deployed in Azure, the following additional resources will be deployed in the production environment.
| Name | Value |
|---|---|
| Login Credentials | The login credentials will be stored in the keyvault under the names irnode-username and irnode-password. |
| Virtual Machines | Two virtual machines will be deployed to serve as the 2 IR nodes. These may need to be scaled out to 3 or 4 nodes depending upon desired performance. They will have the standard virtual machine resources such as OS disks and network interfaces. |
Updated 3 months ago