Transform
Transforming data into analytics and information
Analytics Engineering Flows define the intrabound movement of data (within the lakehouse) to transform the data into usable information for your business.
Empower's model building technology takes care of orchestration and parallelization for you. All you have to define as a user is the logic to transform your data, defined in SQL statements within staging notebooks.
Modeling is the process of manipulating raw data in the Lakehouse into a processed, analytics-ready model. Empower's model building technology takes care of orchestration and parallelization for you. All you have to configure Transformation Tasks and define the transformation logic, as defined in SQL statements within staging notebooks.
Quick LinksThis page covers Transformation Task creation and modification.
- Logging and Monitoring: defines how to use the log page to monitor tasks ("View Runs").
- Schedules and Triggers: describes how to trigger tasks to run on demand ("Preview Run") and schedule tasks to run on a repeating cadence ("Schedule").
- Staging Data Transformation with Notebooks: learn how use notebooks to stage data transformations for model building.
- Configuring Model Building : provides a guide for how to configure model builds with Step Commands using Advanced Options.
Overview
The Transform module is accessible from the left navigation menu.
From this screen, you can view all Transformation tasks within your chosen environment.
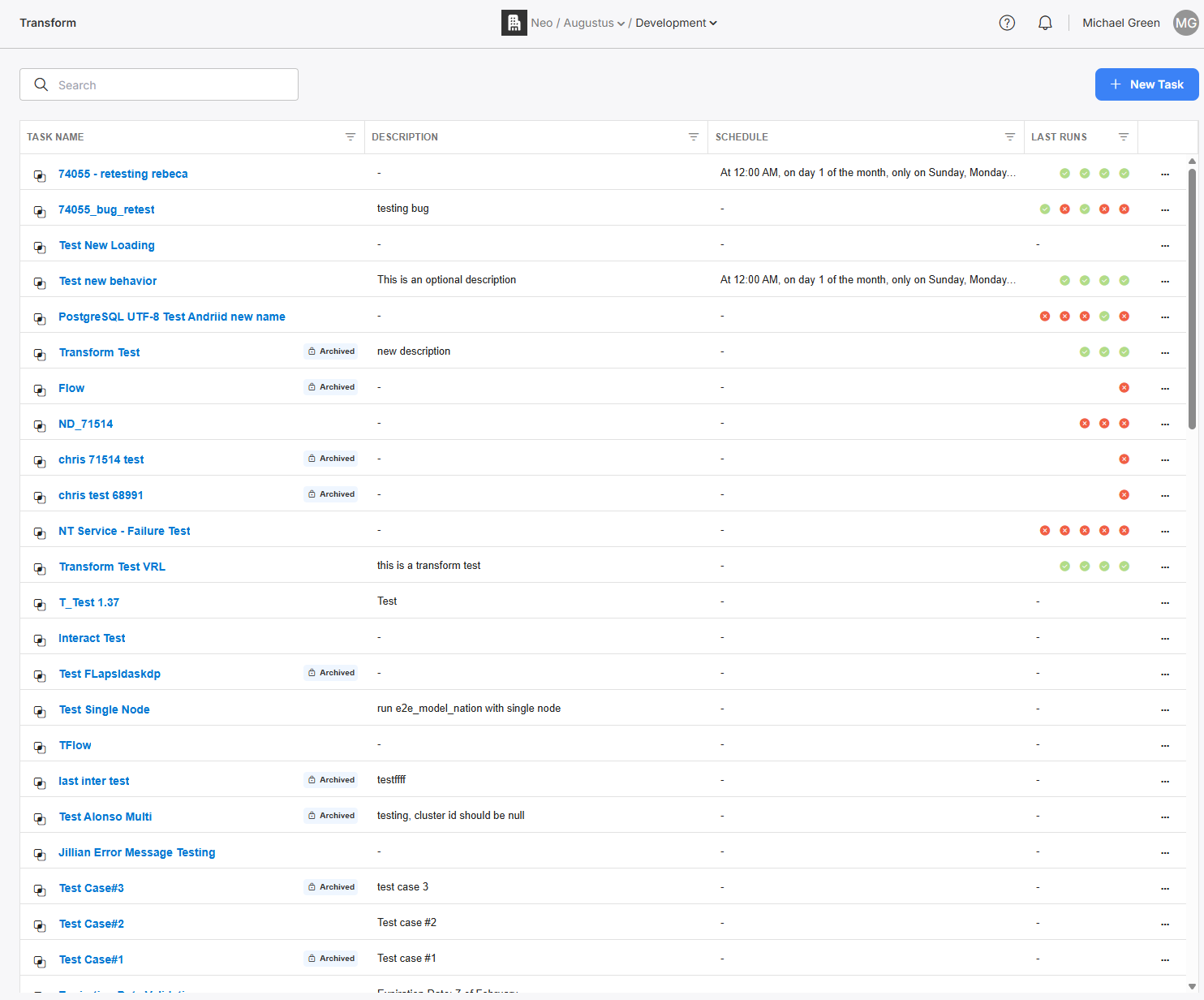
A list of all Transform tasks.
You can search these tasks by name, view configurations or historical run logs, trigger a task to run on demand, view/set/activate scheduling, and create new tasks. You can also navigate to the Models tab for data model management.
Creation
Creating a Transformation Task can be done by simply clicking on "+" at the top of the screen when on the Task tab.
Create a new Transformation Task by clicking "+".
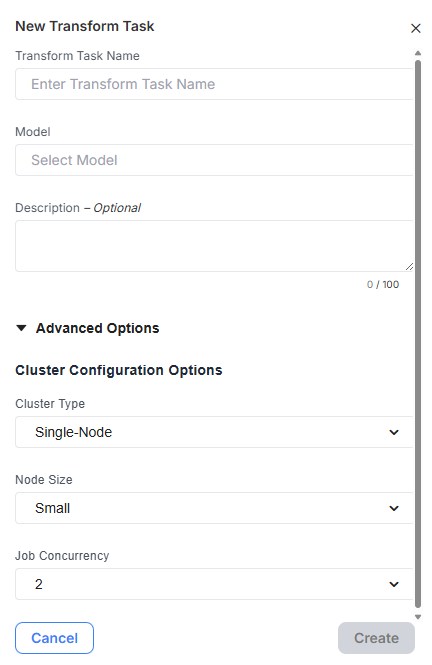
Fill out the name of the task and select an existing Model from the dropdown. Add an optional description to help inform yourself and others about the purpose of this task.
Clicking into the the model field will automatically populate a dropdown list with all existing models. Keep typing to filter this list to the model you want to use.
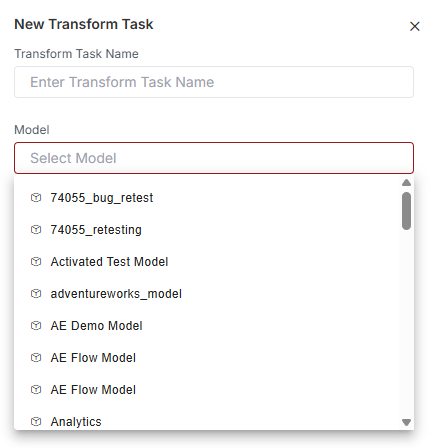
The model field automatically populates with a dropdown of all existing models. You can type into this field to filter the list further.
Advanced Options
For users who have Advanced Options enabled in their Empower instance, you will see additional configuration options. When creating or editing a Transformation Task in the UI, advanced options can be accessed by expanding the 'Advanced Options' accordion.
Cluster Configuration Options
The Cluster Configuration Options provide flexibility in managing computational resources for your data tasks. This feature enables precise control to optimize performance based on your specific task requirements. These options are only available for Spark connectors and will not be available to configure if the associated source is not using a Spark connector.
Configuration Options:
- Cluster Type: The cluster type determines the computing setup for processing your data. There are three options:
- Interactive: This type allows you to specify a specific cluster you want to be used by entering the name of the cluster.
- Single Node: Utilizes one processing unit, suitable for simpler tasks. This option will affect the available configurations for the other settings below.
- Multi-Node: Employs multiple processing units for handling larger or more complex data operations efficiently. Like Single Node, choosing this type will adjust options available in the subsequent settings.
- Node Size: Node size adjusts to the computational power allocated for your tasks within the cluster. Selecting a node size—Small, Medium, or Large—affects the processing capacity and resource availability, allowing you to balance performance requirements against cost.
- Spark Workers: Spark Workers are additional processing units that can be added atop the base worker within a Multi-Node setup. Increasing the number of Spark Workers enhances the distributed computing capabilities, allowing more effective distribution and parallel processing of data workloads.
- Job Concurrency: Job Concurrency pertains to the number of jobs that can run simultaneously within the cluster. By configuring this option, you can enable parallel execution of multiple tasks, maximizing resource utilization and throughput, particularly beneficial for larger node sizes.
Once you fill out the required fields (Name and Model), click "Create" to complete the creation process.

Create is now enabled, now that Name and Model (required fields) have been filled out.
You can now see your newly created task at the top of the page.

Congratulations, you have successfully created an Transformation Task.
INFO: 1 to Many - Models and Transformation TasksModels and Transformation tasks have a 1:many relationship.
This means that a single Transformation Task can only ever be associated with one model at any moment in time. However, a specific model may be associated with many different Transformation Task, all with different schedules (or even no schedule at all!).
As an addendum, you will not be able to change an Transformation Task's selected model post-creation.
Editing
Clicking on the name of a Task will bring you to the Task tab view as shown below with the Overview tab selected by default.
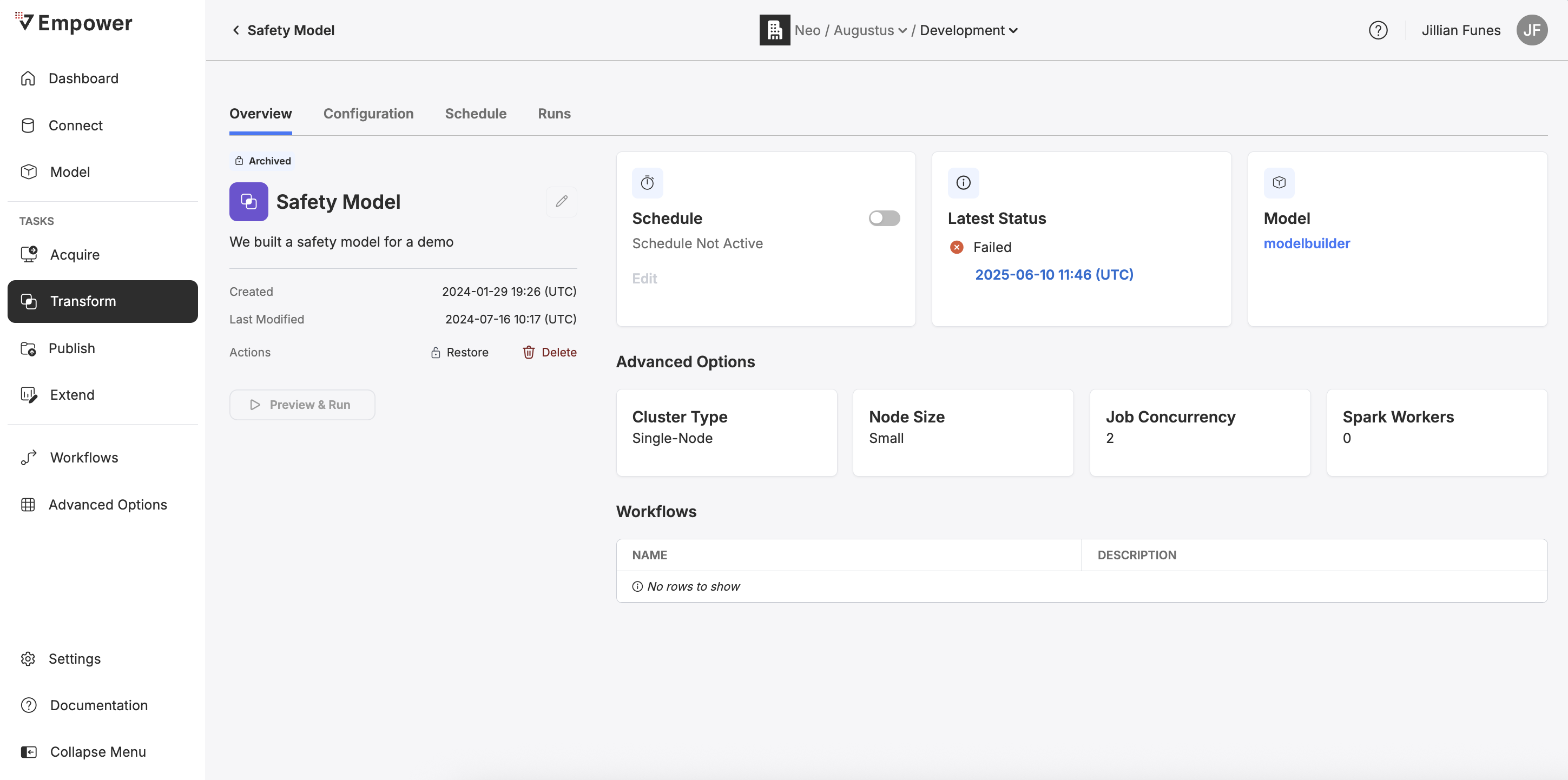
Click on the pencil icon next to the Task name to bring up the edit form where you can update the Task name, description, and advanced options.
INFO: Transformation Task Edit RestrictionsYou can only ever modify the name and description of an Transformation Task. You will not be able to reselect an Transformation Task's associated model.
If you want a different model, create a new Transformation Task and associate the chosen model with it instead.
Deletion
You can delete any existing Tranformation Task by clicking the Delete button from the Task overview tab. Doing so will bring up a menu with one option being to Delete the task.
A confirmation modal will pop up. You must confirm you wish to delete the task in order to complete the deletion process.
Confirm you wish to delete the task and all of its historical logs.
DANGER: Deletion is PermanentTask deletion is a permanent action. Deleting a task will also remove the entire historical log of that task. You will not be able to reverse a task's deletion, so make sure you actually want to perform this action!
Scheduling and Triggering Tasks
To read about how to schedule and trigger Transformation Tasks or any other task type, visit Scheduling Data Tasks.
Configuration
Clicking on the name of a Task and then select the "Configuration" tab on any existing Transform Task to visit its configuration page..
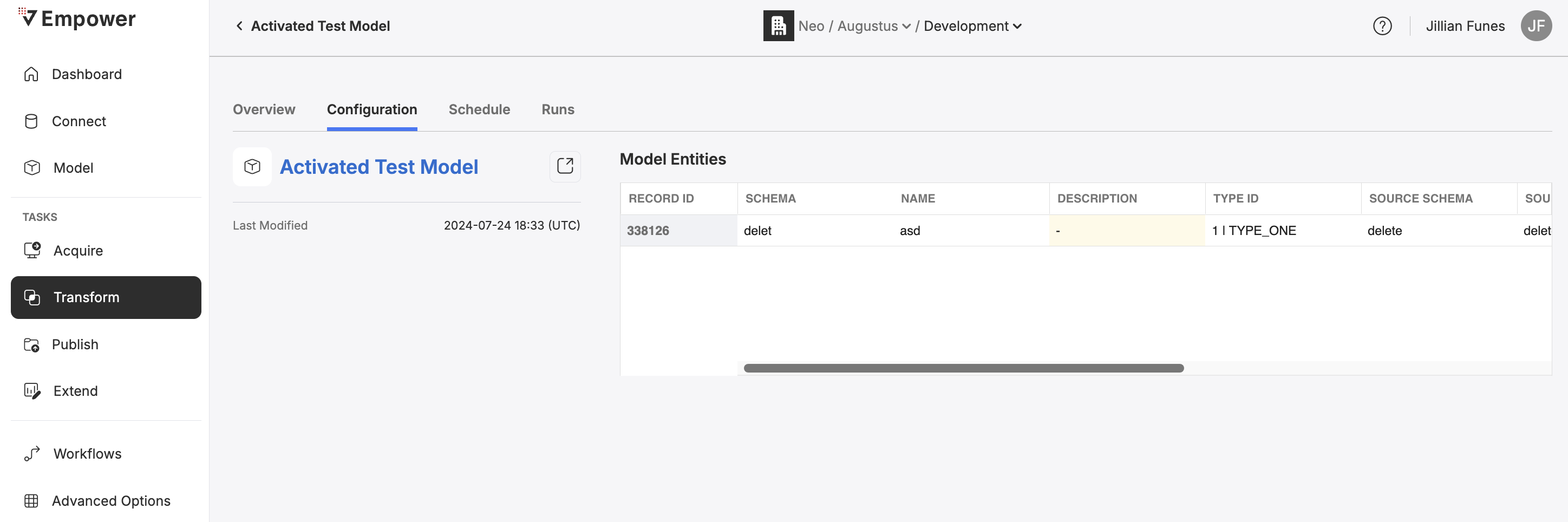
From the configuration page, you can view the associated model and the Model Entities that will be built within the model associated with this task.
Click on the Model name to view and edit the Model's Entity Columns and Entity Dependencies.