Technical Details
Data Migration
This section covers the data migration process itself. Tools are provided for accelerating for automating the data driven upgrade.
DataUpgrade Class
The DataUpgrade class provides a suite of tools for executing the data migration to Dynamics and is the primary interface for the data migration. It handles a class-managed pool of threads which provide acceleration for writing in parallel.
from empowerddu.client import DynamicsClient
from empowerddu import DataUpgrade
client = DynamicsClient(d365_url)
migrator = DataUpgrade(client)Migration Streaming
To facilitate automating the data migration process, the DataUpgrade provides a wrapper around the Spark auto-loader streaming functionality. This will incrementally stream all data from the source and write it to the destination table entity, table_name. If no table name is specified, it can be inferred from the source when the table names match.
from empowerddu.source import ParquetStreaming
# Initizalize a streaming data source; in this case parquet files.
source = ParquetSource(data_location)
migrator.auto_load(checkpoint_location, source, table_name)The auto-loader uses the "available-now" streaming trigger which will process all data available when the auto-loader is started and shut down once all data has been processed.
The auto-loader will checkpoint it's progress in the checkpoint_location directory. This allows the auto-loader to be restarted without reprocessing already migrated data. If restarting the process is needed, simply delete the checkpoint directory and rerun the auto-loader.
Note that auto-loader will always read a minimum of a single file/partition underlying the data source for its incremental process. This means that the data source needs to be pre-partitioned into the desired number of partitions. Regardless of the number of data partitions, the data can still be split into the desired request size by specifying the batch_size parameter in the auto_load method.
Logging
The DataUpgrade class provides a logging interface for tracking the progress of the data migration. The log is recorded in a table with the following schema:
| Column | Type | Description |
|---|---|---|
| table_name | string | The table name being migrated |
| partition_id | integer | The data partition id |
| batch_id | integer | The batch id |
| batch_size | integer | The number of records in the batch |
| write_time | float | The time taken to write the partition |
| time | timestamp | The timestamp the partition write finished |
| error | string | Any error that occurred during the write |
| severity | integer | The severity of the error |
| cause | string | The suspected cause of the error |
| quarantine_table | string | The name of the table failed records were written |
The name of the logging table can be specified in the DataUpgrade constructor. If provided, information on the write status for each batch will be recorded.
migrator = DataUpgrade(client, logging_table="my_database.log")
...
migrator.auto_load(checkpoint_location, source, table_name)
# Display the log table
migrator.read_log().display()Error Quarantine
The DataUpgrade supports a quarantine database to store data if an attempt to write fails. This is useful for debugging and retrying failed writes in combination with the error reported in the logging table. The quarantine area can be specified in the DataUpgrade constructor. If any batches within a partition fail to write, the failed batches will be written to the provided database in a table matching the migrating table's name.
migrator = DataUpgrade(client, quarantine_database="ddu_quarantine")
migrator.auto_load(checkpoint_location, source, table_name)The migration log table will record the table name, in the quarantine_table column, where failed batches were written. The failed batches can be re-read for examination with the load_from_quarantine method and downloaded to an excel file for editting and retry with the download_quarantine method.
# Read failed records from a specific table
df = migrator.load_from_quarantine(table_name) # Parquet path from log table
# Download to an excel file
migrator.download_quarantine(table_name, "dbfs:/ddu_work_dir/table_name.xlsx")Note that the quarantine database tables will be overwritten if the same table is written to quarantine multiple times.
Pipeline Orchestration
To automate the DDU migration process, an example is provided of how to construct notebooks to load a sequence of tables. The notebooks can be attached to a Databricks workflow to automate the process and take advantage of the reduced costs for jobs compute.
Migration Setup
The migrating data should be stored in a data format supported by DDU and already transformed as needed to be written to the destination. For the example, a DDU state table is used to track the migration progress in tandem with the migration log table. The state table has the following schema:
| Column | Description |
|---|---|
| id | The order id the tables will be migrated |
| table_name | The table name being migrated |
| records | The number of records that need migrating |
| validated | If all validation checks have succeeded |
| workers | The number of workers that will be used |
The state table should be loaded with each table that will be migrated. The records column is used to track when the migration of a particular table has been completed. In the event of a crash or restart, completed tables will not be executed again. Once the migration of a table has finished and it has passed all validation tests, the validated column can be updated to true.
Workflows also support multi-step jobs that execute on the same cluster. This supports migration patterns that require execution in multiple steps. Intermediate steps can apply additional transformations, sync data back to the lakehouse from the target environment, or perform other tasks.
Executing a Migration
The migration notebook can be attached to a Databricks workflow. The whole process is idempotent, so each time the job is executed, only data that has not been executed yet will be migrated. This is ensured by counting the number of records already migrated, checking the validation output, and the checkpointing location from the auto-loader.
Migration Dashboard
DDU provides a PowerBI report with every deployment, used to track the status of migrations. The report visualizes the results of the Log table in an intuitive way.
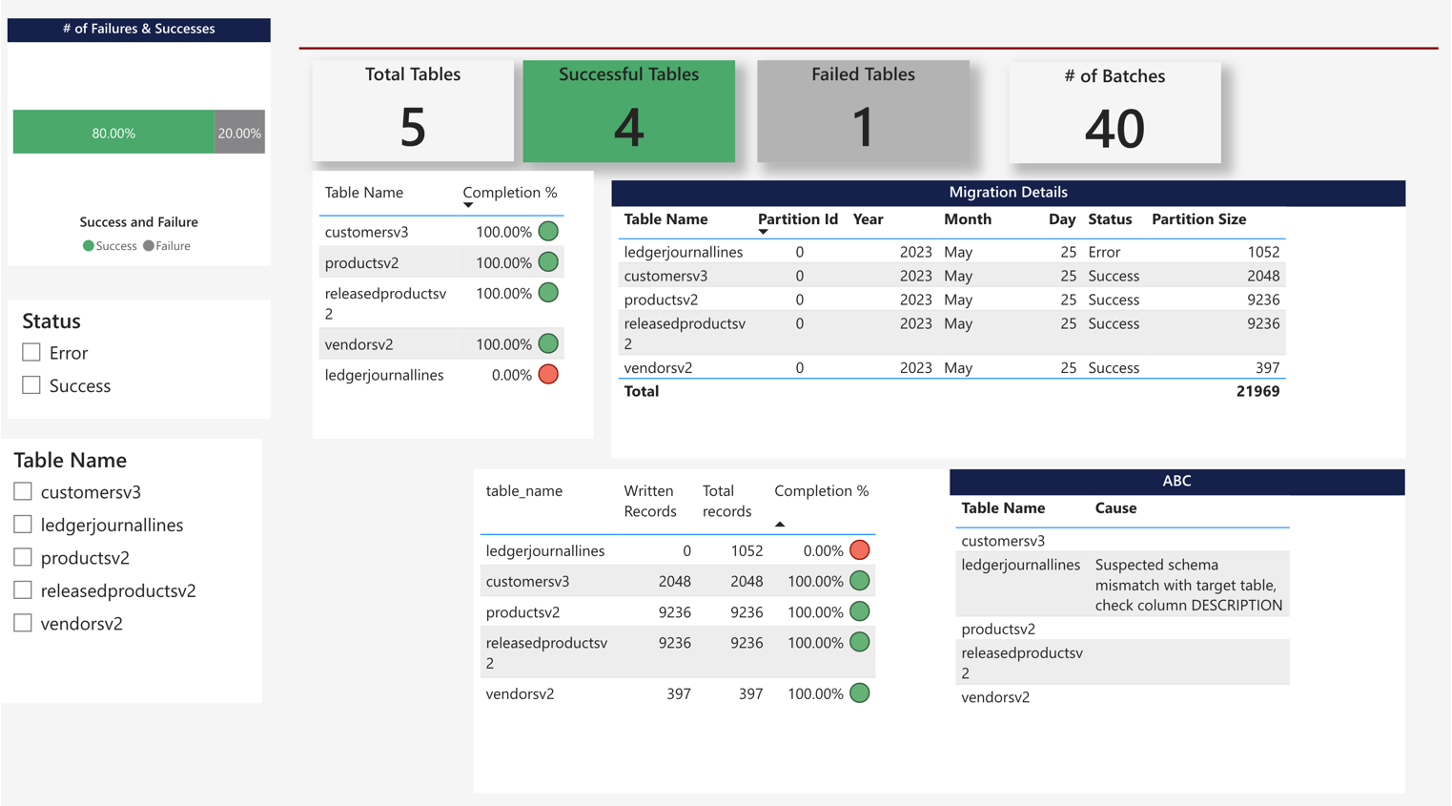
Use it to quicky track progress and identify failing objects, then use the Log table to drill down into the specific batches that are failing.
Dropbox Migration
For direct migration that requires no data transformations, it can be convenient to do a simple upload to a dropbox folder.
It is recommended to use a FileStore dropbox such as "dbfs:/FileStore/tables/ddu_dropbox" to upload files. The files will be moved to an archive directory within the dropbox after being ingested by the pipeline. There are two ways to upload files to the Databricks workspace to input to this dropbox pipeline.
- The first is to use the DBFS upload utility from the Databricks UI. Currently this is found by: "Add" at the top left of the workspace -> "File Upload" -> "upload to DBFS". Specify the dropbox location in the text box, then drag and drop the files.
- The second is to use the Databricks CLI. This is a python package that can be installed with pip. The CLI can be used to upload files to the dropbox location on DBFS directly from any machine. See the Databricks CLI documentation for more information.
A json configuration can be uploaded along with the excel data template files. All configuration parameters are currently optional.
| Parameter | Description |
|---|---|
| target_entity | The name of the target entity in Dynamics. |
| overwrite | If true, the database table will be overwritten. Useful for uploading new templates after errors. |
| atomic | If true, the entity will be migrated in a single transaction. |
| legal_entity | (F&O only) The name of the business legal entity in D365. If not provided or empty, the data will be written to the default legal entity. Leave empty for shared entities |
Here is an example configuration file for two entities. The first file will be migrated to the entity "dynamics_entity_one" in a single transaction. The second file will be migrated to the entity "dynamics_entity_two" and will overwrite the existing table in the lakehouse.
{
"entity_one.xlsx": {
"target_entity": "dynamics_entity_one",
"atomic": true
},
"entity_two.xlsx": {
"target_entity": "dynamics_entity_two",
"overwrite": true
},
}The dropbox functionality is incorporated into three notebooks in the notebooks directory of this repo.
- InitializeDatabase - Initialize the migration database, log table, and state table.
- IngestDropbox - Ingest files from a dropbox folder into delta tables, currently assumed to be excel files.
- DDUMigration - Execute the migration process for tables in the state table.
These three notebooks should be assembled into a Databricks workflow to automate the migration process. The notebooks should be dependencies in the order listed above. The compute for this workflow should include the empowerddu package, the CData JDBC drivers+wrapper, and the spark-excel maven library.
Handling Re-Runs
-
If a migration dies partway through, simply rerun the migration pipeline. The migration will pick up where it left off.
-
Uploading additional new files/tables to be migrated is no problem and can be handled by the system. Any already completed table migrations will not restart.
-
To migrate a new version of an object, such as after an error occurred, set the "overwrite" configuration option to True. After uploading the new table version, the migration process will restart from the beginning for that table. The log records will be maintained for book-keeping.
-
If desired, it is possible to start from a clean slate by specifying a new database in the pipeline input. It is also possible to change the pipeline parameter "drop_database" and "reset_checkpoints". WARNING: This will drop the database and all tables within it, then reset the streaming checkpoints.
Edit Grid
As mentioned, when a batch fails to write to the target, for any reason, the failed batch is written to a quarantine database. Optionally, these failed records can be downloaded for editting and re-uploading. This can be done manually from the DataUpgrade class:
migrator = DataUpgrade(client, quarantine_database="ddu_quarantine")
migrator.download_quarantine(table_name, "dbfs:/ddu_work_dir/table_name.xlsx")This occurs automatically in the dropbox pipeline when the parameter download_quarantine is set to "True".
Updated 6 months ago