Empower Data Platform v1.31
Key Changes and Improvements
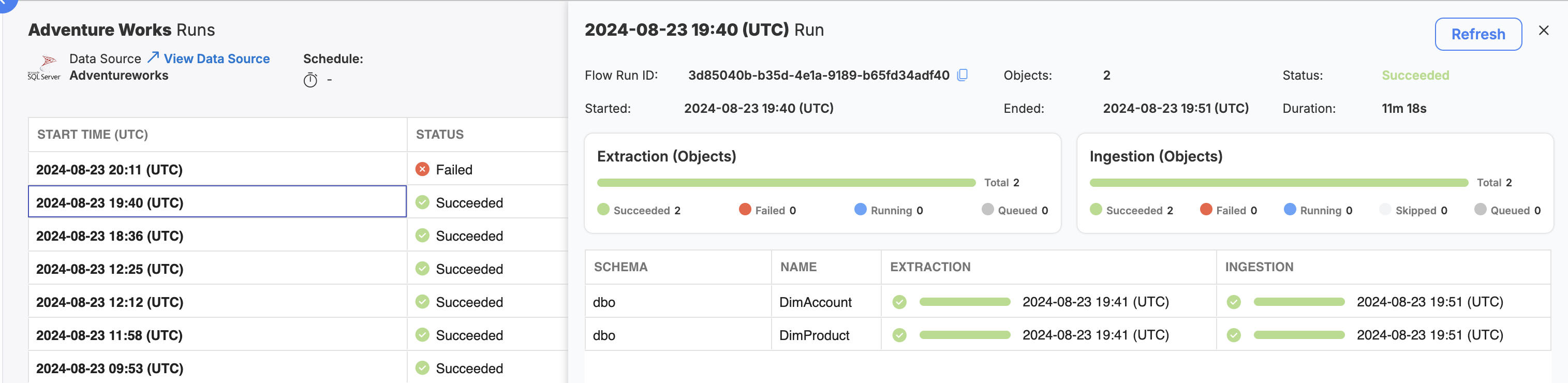
- Data Acquisition Flow Monitoring and Logging: You can now observe historical and currently-running data acquisition flows in an intuitive way! Visit the docs to learn more about how to use this new feature in your deployment.
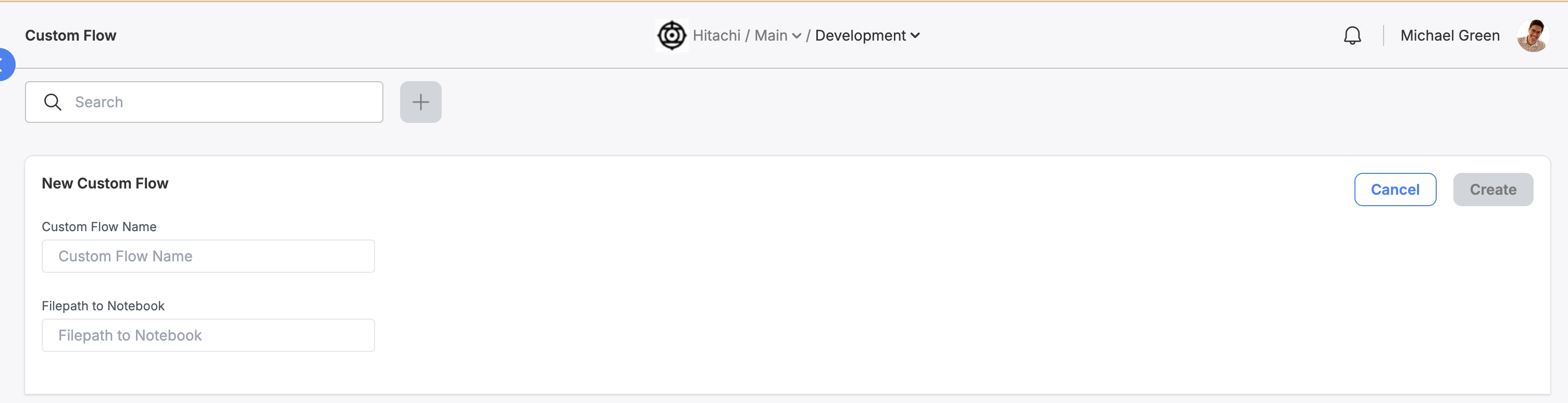
BETACustom Flows : Empower now allows for more flexibility than ever before. Want to execute a notebook on a schedule? You can now configure custom flows to do just that! Visit the docs to learn more about how to use this new feature in your deployment.
Data Acquisition Flow Monitoring and LoggingIntroducing a new way to monitor your platform, starting with Data Acquisition!
Data Acquisition flows now provide robust logging capabilities, including object-by-object extraction and ingestion granularity as data is landing in your lakehouse. Visit the docs to learn more about how to use this new feature in your deployment.
Over the next few releases of Empower, we will be rolling out updates and new features for all of the flow types in the UI today. Stay tuned to our Product Release Roadmap for the newest information!
BETACustom FlowsCustom flows allow for the execution of a single notebook in your deployment. All you need to do is define the name of your custom flow and the filepath to the notebook in your lakehouse. The notebook will then executed anytime the flow runs.
Custom flows provide much needed flexibility apart from the specialized Data Acquisition, Analytics Engineering, and Publishing flow types. We strongly recommend trying to use one of these formal types first, as they provide additional functionality (like specialized logging capabilities) that custom flows will not have. But if you are ever needing to just "run a notebook", you can now use custom flows to do so!
NOTE: custom flows are currently feature flagged in the UI by default. Talk to your delivery team today for how to turn this on for your deployment.
Visit the docs to learn more about how to use this new feature in your deployment.
Itemized Changelog
Enhancements & New Features
- Cluster Configuration: Added support for cluster configurations in Data API, changes in ingestion execution per source, and use of cluster configuration in ingestion and modeling.
- Batch Extract Updates: Spark connectors can now extract data in batch, resulting in more efficient cluster utilization. This will be rolled out slowly over several releases.
- Metadata Error Messaging: Enhanced metadata error messaging for failed metadata extraction.
- Metadata Catalog Delta Ingestion: This setting is now automatically enabled when an object is enabled.
- Config Migration - Data Flows: Data flows (Data Acquisition, Analytics Engineering, and Data Publishing) are feature flagged to be promotable. Talk to your delivery team with getting access today.
- Data Acquisition Flow Logs: Data Acquisition flows now contain interactable flow log history, including flow run logging on an object-by-object basis.
- Custom Flows: Currently in Beta, custom flows are a new flow type available under a feature flag in the 1.31 release. A custom flows will enable the execution of a single notebook, specified in its configuration. Talk to your delivery team with how to enable the custom flow flag in your environment today.
Bugfixes
- Fixed issues causing ADF pipelines to fail, including problems with data acquisition, PL_MODEL_DATA, META_SPARK_PL, and more.
- Resolved issue where service returned a 500 error on getting user photos.
- Corrected failures in data ingestion and extraction processes. Addressed issues with wrong associations and failed batch ingestion.
- Fixed a problem with internal PBI reports.
- Addressed various UI bugs related to column titles in uppercase and incorrect display of end times and statuses across different parts of the application.
- Corrected display issues on the Data Migration and Settings pages, including active migrate buttons and information text placement.
- Fixed issues with the status field not updating after refresh and error modals not opening as expected.